

はじめに
こんにちは、データ活用推進部 レコメンドチームの寺井とデータ基盤開発部 ML基盤チームの上田です。レコメンドチームでは、機械学習モデル(特にレコメンド)の設計・実装・評価の役割を担い、ML基盤チームでは機械学習モデルを安定的かつ効率的に運用するためのインフラ構築を担当しています。
本記事では、DMM TVにおいて、マイクロバッチを用いたニアリアルタイムレコメンドシステムを導入したので紹介します。
マイクロバッチとは、バッチ処理の実行間隔を数分単位まで短縮した仕組みです。従来は日次バッチでレコメンドリストを更新していましたが、本施策ではユーザ行動に合わせてほぼリアルタイムにレコメンドリストを入れ替えられるようになりました。
背景
DMM TVでは、さまざまな種類のレコメンドを用いてパーソナライズを図っています。その中でも、Topページに設置している『視聴した作品をもとにしたitem2itemレコメンド棚(下図の「〇〇」をご覧になったあなたへ)』があります。当社ではこのレコメンド棚のことを履歴i2i棚と呼んでいます。
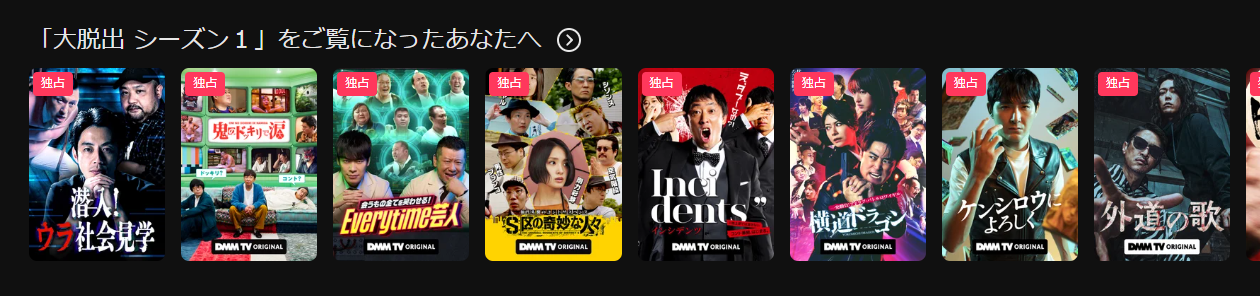
この棚は CTR, CVRなどのパフォーマンスが高いレコメンド棚ではありましたが、以下の2つの課題感がありました。
- 従来の日次バッチの場合だとユーザの前日までの視聴作品に対するi2iレコメンドが、次の日に1日中表示され続ける。ユーザは1日に何作品も視聴する可能性があり、それらに対するi2iレコメンドが出来ていないことで機会損失を生んでいる可能性がある。
- 履歴i2iは、直近に視聴した3作品から最大3棚まで生成される。そのため、従来の日次バッチの場合、仮に視聴が3作品未満の新規ユーザについては生成される棚が3棚未満の日が発生しうるため、課題1と同様に、機会損失を生んでいる可能性がある。
これらの課題を解決するべく、今回は5分間隔というマイクロバッチによるニアリアルタイムな履歴i2iを導入しました。リアルタイム性が高まることで、ユーザの視聴行動(興味関心)に追従することが可能となり、機会損失を最小限に抑えることが期待できます。
提案手法
上記の課題を解決するために、Cloud WorkflowsとCloud Run jobsを組み合わせたマイクロバッチ処理を導入し、レコメンドを高頻度で更新する仕組みを構築しました。
構成とアーキテクチャ選定
今回のマイクロバッチを構築するにあたり、ワークフローエンジンとしてCloud Workflowsを、メインの処理基盤としてCloud Run jobsを選定しました。MLを使わないデータ加工処理ではCloud Workflowsを用いた既存実装があり、開発コストを低く抑えられるためです。
私たちが他の日次バッチ処理で標準的に利用しているVertex AI Pipelinesは、リソースのプロビジョニングに数分の起動オーバーヘッドが存在します。そのため、5分間隔という高頻度での実行が求められる今回のマイクロバッチの要件には不向きでした。Cloud Workflows, Cloud Run jobsは起動オーバーヘッドが小さく、軽量な処理のトリガーとして最適だったため、今回のアーキテクチャとして採用しました。
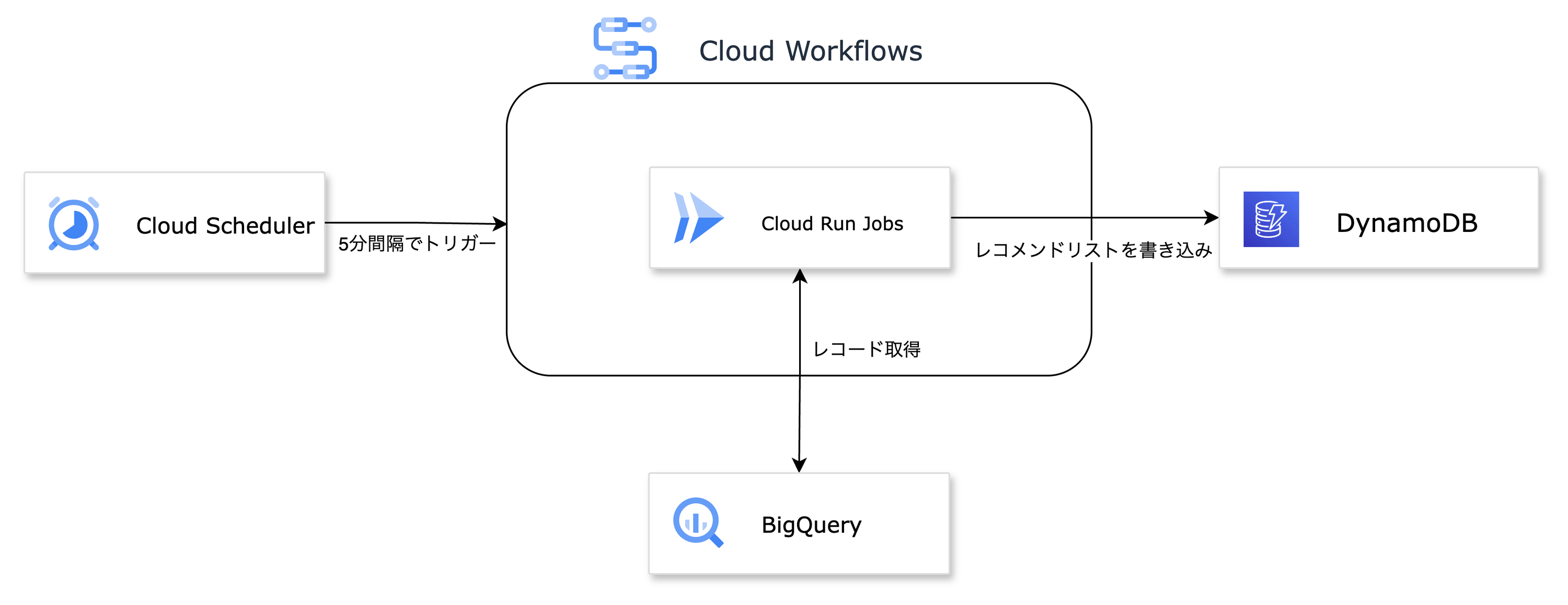
処理フローは以下の通りです。
- Cloud Scheduler: 5分間隔でCloud Workflowsを定期実行します。
- Cloud Workflows: マイクロバッチ全体のオーケストレーションを担い、BigQuery Jobの実行やCloud Run jobsの起動をします。
- Cloud Run jobs: レコメンド生成、DBへの書き込みといった処理を実行します。
マイクロバッチの選定理由
DMM TVの履歴i2iレコメンドでマイクロバッチ方式を選定した理由は、主に以下の2点です。
- 秒単位のリアルタイム性が不要だった
- 実装・運用保守・コストのバランスを重視した
1. 秒単位のリアルタイム性が不要だった
DMM TVの主要コンテンツであるアニメは1話あたり約25分と、視聴に一定の時間を要します。ユーザが1つのエピソードを見終え、次の作品を探すタイミングでレコメンドが最新の状態に更新されていれば、十分に快適なユーザ体験を提供できます。そのため、秒単位での厳密なリアルタイム性は不要と判断し、数分程度の遅延を許容するマイクロバッチが今回の要件に合っていました。
2. 実装・運用保守・コストのバランスを重視した
私たちのML基盤には、日次でVertex AI Pipelinesを実行するバッチ基盤と、Online Feature Storeと推論APIを利用したリアルタイム推論基盤の主に2系統があります。
リアルタイム推論基盤の詳細については以下の記事にまとめているのでよろしければご覧ください。 note.com
弊社ではリアルタイム推論基盤の構築・運用実績もあり、技術的にはリアルタイム方式も選択可能でした。 しかし、リアルタイム推論はユーザの行動に即時反応できる一方、以下のようなトレードオフが存在します。
- コスト: 推論エンドポイントの常時稼働が必要。インフラコストが高くなる傾向にある。
- 複雑性: 推論エンドポイントやストリームデータパイプラインなど、多くのコンポーネントでシステムが構成されるため、開発・運用コストが増大する。
今回は数分程度の遅延が許容できる要件だったため、リアルタイム性のメリットよりも、開発効率、運用負荷の低さ、コスト効率といった観点でマイクロバッチの利点が上回ると判断しました。非常にシンプルな少数コンポーネントのアーキテクチャにより、MLエンジニアは追加の推論エンドポイントやストリーミングパイプラインの開発に時間を費やすことなく、MLエンジニアがロジックの開発に集中でき、短期間での施策リリースを実現しました。
実験
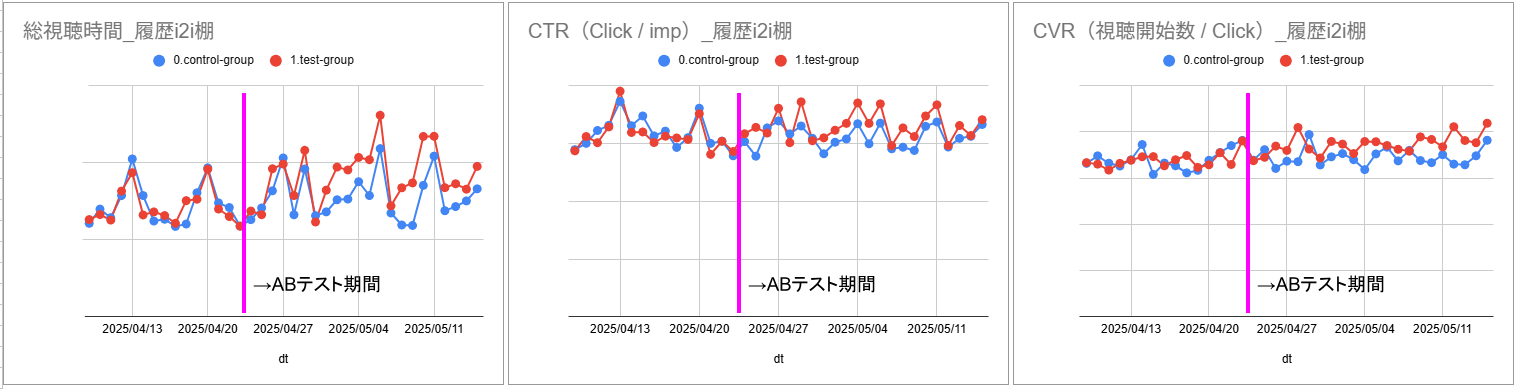
14日間のA/Bテストを行って効果を検証しました。
結果
履歴i2i棚経由の指標
履歴i2i棚経由の各種指標は以下の表の通りです。いずれにおいても、従来の日次更新による履歴i2iからは大幅に数値を上回りました。
| 評価指標 | Test群 / Control 群 (%) | 統計的有意差 (p値 < 0.05) |
|---|---|---|
| 総視聴時間 | +18.4% | あり |
| CTR (Click / imp) | +7.5% | あり |
| CVR (視聴開始数 / Click) | +8.3% | あり |
サービス全体の指標
履歴i2iに関係なく、DMM TVのサービス全体としての指標は以下の表に示します。こちらは履歴i2i経由の指標に比べると、あまり大きな影響は見られませんでした。
| 評価指標 | Test群 / Control 群 (%) | 統計的有意差 (p値 < 0.05) |
|---|---|---|
| 総視聴時間 | +1.5% | なし |
考察
履歴i2i棚経由の各種指標について有意に勝ち傾向が出ていたことから、棚の利便性が向上したといえそうです(冒頭の課題1の解決に寄与)。 総視聴時間に関して、履歴i2i棚経由では有意に向上したにも関わらず、全体でそこまで影響がなかったのは、そもそも履歴i2i棚が全体視聴に与える割合が限定的であったからと考えられます。 また補足として、新規ユーザ(Trial会員)において履歴i2i棚のimp数の増加が確認されており、棚表示件数が増えていたことが見込まれます(冒頭の課題2の解決に寄与)。
改善点
履歴i2i棚に関すること
現状のロジックでも一定のユーザ満足度は獲得出来ているとは思いますが、ユーザにとって新規性のあるレコメンドを提示するようなモデル設計にすることで、さらにDMM TV全体における総視聴時間を増やせるのではと考えています。 現状だと、レコメンドされなくても(検索などの)他の経由で視聴していたであろう既知の作品を提示している側面が強いように見えます。特に、続編や関連作品を多くレコメンドしていることがあり、利便性は良いのですが、新規性という観点では課題があります。
マイクロバッチ基盤に関すること
BigQueryのコスト最適化
現在、マイクロバッチで実行されるクエリは、コスト管理のしやすさからオンデマンド料金で運用しています。 当初、日次バッチ等で利用している既存のReservationと共用しましたが、マイクロバッチの実行頻度(5分ごと)が原因で、BigQueryのオートスケーリングが非効率に動作する問題が判明しました。具体的には、スロット消費の少ないマイクロバッチに対し、他のジョブが稼働していない時間帯にも過大なスロットが割り当てられ続けてしまう、という状況でした。 対策として、マイクロバッチ処理専用のReservationを将来的に作成することを検討しています。現状はまだマイクロバッチ基盤を利用した施策は少ないためオンデマンド料金が最適です。今後施策数が増加してきたタイミングで、ベースラインスロット等を調整した専用Reservationへ移行することにより、パフォーマンスを維持しつつさらなるコスト最適化が見込めます。
ワークフローエンジンの統一
現在、日次で実行しているバッチ処理(Vertex AI Pipelines)と、今回のマイクロバッチ処理(Cloud Workflows)でワークフローエンジンが異なり、MLワークロードの運用が二元化しています。将来的にはVertex AI Pipelinesへのワークフローエンジン統一を計画しており、共通コンポーネントの再利用による開発効率向上や、ログ・実行ステータス監視の一元化といった運用面のシンプル化が期待できます。
特に、本記事執筆時点(2025年6月)でプレビュー版である Persistent Resourceの活用を検討しています。これはパイプライン実行用のリソースをプールとして確保しておく機能で、今回私たちがWorkflowsを選定する決め手となった、Vertex AI Pipelinesの起動オーバーヘッドを大幅に削減できます。
おわりに
本記事では、DMM TVにおける履歴i2i棚のレコメンド更新をマイクロバッチで実現した事例を紹介しました。
定性的にも履歴i2i棚が視聴行動に追従してニアリアルタイムに更新されるのは、体験が良いなと感じました。また、履歴i2iの特性上、視聴毎にガラッとレコメンドアイテムが変わるので、リアルタイム化するにあたってもっとも効果がでそうな棚であり、そこから着手できたのは良かったと思います。
最後に、DMMデータサイエンスグループでは一緒に働いてくれる仲間を募集しています。ご興味のある方は、ぜひ下記の募集ページをご確認ください。