

- はじめに
- アーキテクチャ設計の具体変化とコード構成の詳細
- 「イベントストーミング」から「実装」への変換プロセス
- テスト戦略の変化
- 設計を「知識」として蓄積する
- 数値で示す改善
- まとめと今後の展望
- 宣伝
はじめに
こんにちは。プラットフォーム開発本部 カスタマーサポートプラットフォームグループ(CSPグループ)でバックエンド開発を担当している白石です。
前回の坂本さんが書いた記事「持続可能なシステムを目指してプロダクトをリアーキテクトしました〜ドメインモデリング導入編〜」では、私たちがリアーキテクトに至った背景や、ドメインモデリングをどのように取り入れたのかを紹介しました。まだご覧になっていない方は、ぜひそちらを先に読んでいただくと理解が深まると思います。
👉 前編はこちら(ドメインモデリング導入編)。developersblog.dmm.com
今回の「実践編」では、そのモデリングをどのようにコードに落とし込み、設計や開発体験がどう変わったのかを具体的にご紹介します。 また、アーキテクチャの改善によって、AIのような新しい技術も取り入れやすくなった背景についても触れています。
アーキテクチャ設計の具体変化とコード構成の詳細
まず初めに、「アーキテクチャ設計を見直すことで、具体的に何が変わったのか」について紹介します。
私たちはこれまで、肥大化した service 層に苦しみ続けてきました。
特に、service,dao 層が密に相互依存しており、責務の分離が曖昧でした。
その結果、ドメインロジック・永続化・外部連携といった関心ごとが混在し、保守やテストの妨げとなっていたのです。
そこから DDD に基づくレイヤー設計へと移行することで、驚くほどコードが読みやすく、管理しやすくなったのです。
この章では、その構造の変化と意識したポイントを具体的にお伝えします。
アーキテクチャ設計の変化
下記はアーキテクチャ設計の変化を比較したものです。
クライアント
⬇️⬆️
response層 ←→ handler層...クライアントからのリクエストを受け取り、レスポンスを返す。
⬇️⬆️
service層...受け取ったリクエストに応じて処理を行うビジネスロジックを置く。
⬇️⬆️
dao層...DBや外部サービスとやりとりし、データの永続化を行うための処理を置く。
⬇️⬆️
DB/AWS/外部APIなど
クライアント
⬇️⬆️
[ Interface層 ]
Web/HTTPインターフェース。リクエスト・レスポンス処理を担う。
⬇️
[ UseCase層 ]
ユースケース単位でアプリケーションの流れを制御。ドメインロジックを呼び出す。
⬇️
[ Domain層 ]
Entity / ValueObject / Domain Service を中心とした純粋なビジネスロジック。
⬆️
[ Infrastructure層 ]
DBアクセス・外部API・メール送信などのI/O処理を扱う実装群。
⬇️
DB / 外部API / AWS等
この構造への移行によって、以前抱えていた課題が明確に解消され、大きな改善効果が得られました。
課題1: 各層の相互依存関係により、仕様変更の修正影響範囲が多い
以前は handler / service / dao などが相互依存しており、特に dao 層の修正が上位の service 層や handler にまで影響することが少なくありませんでした。
→ 上位層から下位層へと一方向の依存構造を採用することで、修正の波及範囲が限定され、ドメインロジックやUIの変更に強い構造になりました。
課題2: service 層に複数の責務が集中し、メンテナンス性が低下していた
ビジネスロジック、ユースケースの制御、外部サービスとの連携、データ永続化などがすべて service 層に混在しており、巨大で可読性の低いメソッドが生まれやすい状態でした。
// UpdateHogehoge 長くて可読性の低いService層メソッド func (a *hogehoge) UpdateHogehoge(p *Params) (*Mogumogu, error) { // パターンA if p.Hoge != nil { // AのなかのパターンB if B { // ...省略 // A-BのなかのパターンC if C { // ...省略 } // A-BのなかのパターンD if D { // ...省略 } // 処理が続く // A-BのなかのパターンE if E { // その他、延々と続く悲観的排他処理 // ...省略 } } } return mogumogu, nil }
→ ユースケース単位に UseCase 層を設け、ドメインロジックは Domain 層に切り出すことで、ユニットテストの対象が明確化され、テストのしやすさと変更時の影響範囲の予測可能性が向上しました。
課題3: service層のdaoへの依存が大きかった
dao は interface 化されていたものの、利用方法が統一されていませんでした。その結果としてservice 層が直接依存し、環境差分やテストの切り替えが困難でした。
アーキテクチャ設計の変化後の見かけの役割は変わりませんが、アーキテクチャ上の位置づけと依存構造が明確化されたことで、設計全体が大きく変わりました。 具体的には以下の違いがあります:
- dao層はservice層から直接呼ばれることもあり、抽象化はあっても徹底されていませんでした。
- Infrastructure層では、Repositoryなどのインターフェースをdomain層に置き、依存関係は常に上位層から下位層への一方向になるよう整理されました。
- これにより、UseCaseから見たときにI/Oは常に「差し替え可能な部品」として扱われる構造が実現され、環境差分の管理やテストの切り替えが設計レベルで支援されるようになりました。
→ 単に層の名前を変えたのではなく、「どこが何に依存してよいのか」のルールが設計に組み込まれたことで、保守性と可搬性の高いアーキテクチャに進化しました。
コード構成の詳細
※本記事内で登場する Announcement や DraftArticle といったドメインモデルの背景や構造については、前回記事「ドメインモデリング導入編」で紹介しています。未読の方はそちらをご覧いただくと理解しやすくなります。
Domain層
Entity / ValueObject / Aggregate を中心に構成され、整合性を保証するロジックを担います。
例として、ドメイン (Announcement) における 告知公開の状態の変更、関連エンティティ(DraftArticle)との連携、時刻の記録、例外処理などがすべてドメイン内部で一貫して行われます。
このように、ドメイン層ではアプリケーションからの呼び出しによって状態の変化をもたらす「操作」を定義します。
永続化やI/Oには関与せず、ドメインルールと整合性にのみ責任を持つ構成としています。
※後の章『「イベントストーミング」から「実装」への変換プロセス』で詳しく解説します。
UseCase層
ユースケースごとに構造体(例:publishAnnouncementUseCase)を定義し、1ユースケース=1構造体の対応で責務を明確化します。
UseCase層の主な責務は、アプリケーションの処理フローを調整することであり、以下の要素を含みます:
- トランザクション制御(例:
u.dbConnection.WriterDB.Transaction(func(tx *gorm.DB) error) - ドメインモデル(Aggregate)への命令(コマンド)実行
- 永続化処理(Repositoryインターフェースを通じた保存)
一方で、ドメインロジック(状態遷移や制約判定)やDBアクセス実装(SQL/GORMなど)は一切含みません。
特に、トランザクション制御については、「Infrastructure層」、「UseCase層」のどのレイヤー(層)でトランザクション実装すべきか議論の余地はあると思います。
ですが、私たちのチームでは「アプリケーション全体の整合性を保証するための流れの制御」として、UseCase層の責務としています。
※後の章『「イベントストーミング」から「実装」への変換プロセス』で詳しく解説します。
Infrastructure層
Domain層の Repository インターフェースを実装し、DBとの永続化処理を担当します。 Aggregate全体(例:Announcement)を保存・更新できるよう構成されており、トランザクション単位で操作されます。 各 Repository 実装は、ドメインモデル(例:Announcement や Article)に依存しています。 これはドメイン層で定義されたインターフェースを実装するために必要な依存であり、 永続化処理を Infrastructure に閉じ込めることで、UseCase やドメインロジックから I/O 処理を切り離す構造を維持しています。
func (r *announcementRepository) Update(ctx context.Context, model *model.Announcement, updatedAt time.Time, opts ...db.TxOption) (*model.Announcement, error) { tx := db.GetTxFromTxOption(opts...) if tx == nil { tx = r.dbConnection.WriterDB } dbAnnouncement := &announcement{ ID: model.ID(), LastUpdateProductUser: model.LastUpdateProductUserName().Value(), LastPublishedAt: model.LastPublishedAt(), ClosedAt: model.ClosedAt(), UpdatedAt: time.Now(), DeletedAt: model.DeletedAt(), } result := tx.WithContext(ctx). Where("updated_at = ?", updatedAt.Format("2006-01-02 15:04:05")). Select("id", "last_update_product_user", "last_published_at", "closed_at", "updated_at", "deleted_at").Updates(dbAnnouncement) if result.Error != nil { return nil, apperror.WrapError(apperror.ErrTypeDBAccessError, result.Error) } if result.RowsAffected == 0 { return nil, apperror.NewErrorForClient(errTypeOptimisticLock, "Optimistic concurrency control: update rejected due to stale data.") } return dbAnnouncement.convertToModel(), nil }
Interface層(Handler)
クライアント(HTTP/JSON等)からのリクエストを受け取り、対応する UseCase を呼び出す責任を担います。
役割は「I/Oの取り扱い」に限定されており、バリデーション・リクエストパース・レスポンス生成などを担当し、ビジネスロジックは一切持ちません。
func (h announcementHandler) PublishAnnouncement(c *gin.Context) { type URIAnnouncementIDParams struct { AnnouncementID int `uri:"announcement_id" binding:"required"` } var uriParams URIAnnouncementIDParams if err := c.ShouldBindUri(&uriParams); err != nil { wrappedErr := apperror.WrapError(handler.ErrTypePathParamError, err) _ = c.Error(wrappedErr) return } var req openapiannouncementadmin.PublishAnnouncementV2JSONRequestBody if err := c.ShouldBindJSON(&req); err != nil { wrappedErr := apperror.WrapError(handler.ErrTypeRequestBodyParamError, err) _ = c.Error(wrappedErr) return } if err := handler.ConvertStructTimeFieldsToJST(&req); err != nil { _ = c.Error(apperror.WrapError(apperror.ErrTypeValidationError, err)) return } publishDTO, err := h.publishUsecase.Execute(c.Request.Context(), uriParams.AnnouncementID, req.Updater, req.BeforeUpdatedAt) if err != nil { _ = c.Error(err) return } response := openapiannouncementadmin.NewUpdated(publishDTO.UpdatedAt) c.JSON(http.StatusOK, response) }
「イベントストーミング」から「実装」への変換プロセス
前編ではイベントストーミングの分析過程を丁寧に紹介しましたが、それが実装にどう結びついたのかは省かれています。モデリングした図が実装につながらなかったら意味がない。 そうならないよう、私たちはイベントストーミングを「図で終わらせない」工夫をしました。どうやって「誰が」「何をする」「何が起きる」の流れをコードに落とし込んだのか? この章では、実際の告知機能を題材に振り返ります。
例: 告知の公開機能
※ 告知機能における「下書き」「公開」などの状態変化の説明
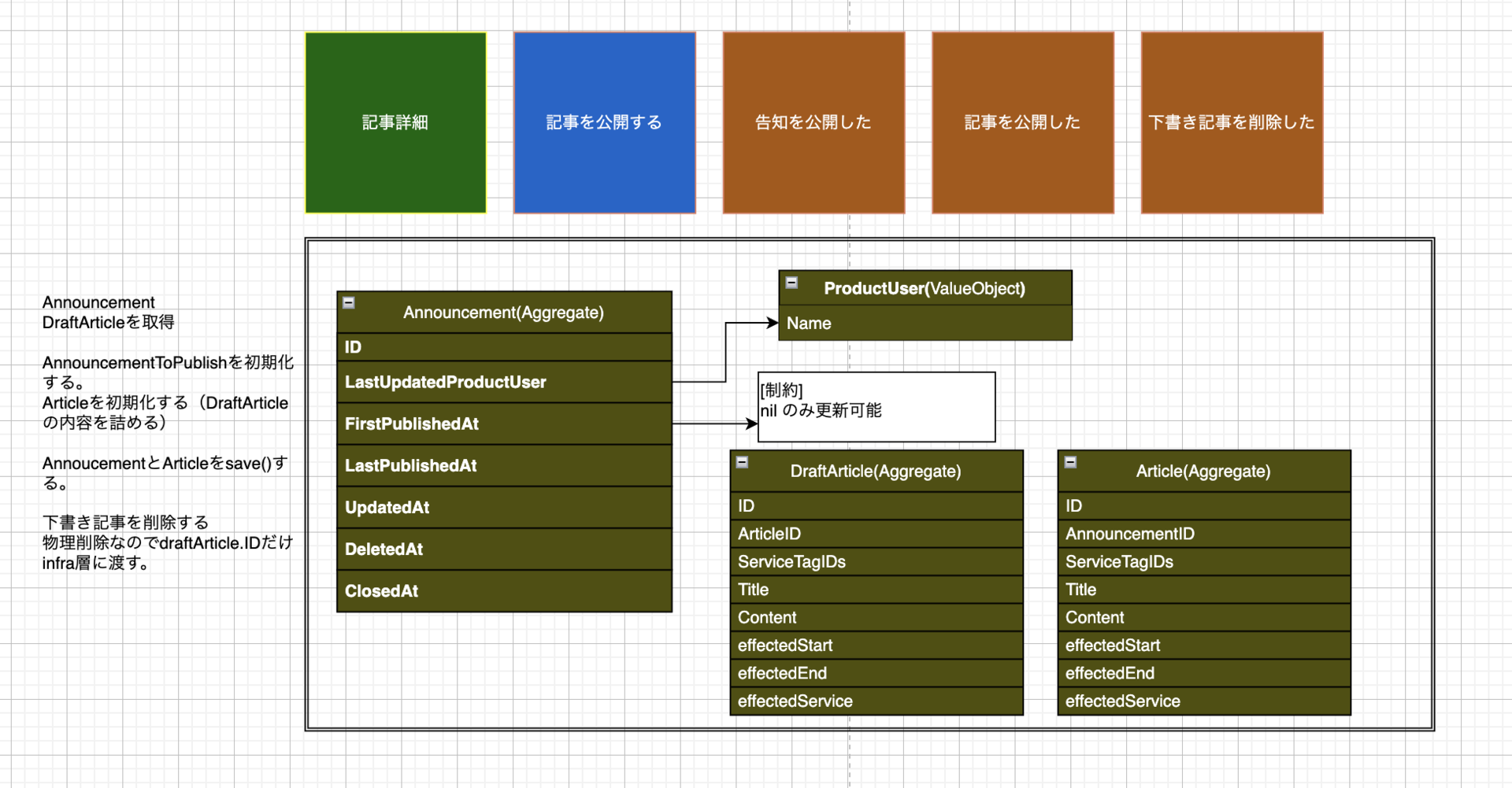
下記に変換手順と変換後の作業を紹介します。
1.ドメインモデル から実装への変換プロセス
イベントストーミングによってユースケース(例:記事を公開する)と、それに伴って発生するイベント(例:告知公開、記事公開、下書き削除)を洗い出しました。これらをもとに、必要なドメインモデルとそれぞれの責務を定義しています。以下はその一部の例です。
| 名前 | 内容/役割 | モデル分類 |
|---|---|---|
| Announcement(告知) | 告知の情報(FirstPublishedAt, LastPublishedAt, SiteType など)を保持する | Aggregate |
| DraftArticle | 公開前の下書き記事の内容(Title, Content, 有効期間 など)を保持する | Aggregate / Entity |
| Article | 公開する記事の内容(Title, Content, 有効期間 など)を保持する | Aggregate / Entity |
| ProductUserName | 操作ユーザー情報を保持する | ValueObject |
type Announcement struct { id int siteType SiteType lastUpdatedProductUser ProductUserName firstPublishedAt *time.Time lastPublishedAt *time.Time closedAt *time.Time ... } type DraftArticle struct { id int articleID int ... } type Article struct { id int announcementID int ... } type ProductUserName struct { name string }
- ValueObjectの活用(例: ProductUser など)
ドメインロジック内で使われる重要な値(たとえば更新者や識別子など)は、単なる文字列やプリミティブ型ではなく ValueObject として明示的に型を定義しました。
例:ProductUser は "ユーザー名が空でないこと" などの制約を内部に閉じ込めることで、利用箇所で毎回同じバリデーションを書く必要がなくなりました。
ValueObjectの導入により、「正しい値しか生成されない」ことが型で保証されるため、バグの予防効果が大きく、テストの単純化にもつながりました。
type ProductUserName struct { name string } func NewProductUserName(name string) (*ProductUserName, error) { if name == "" { return nil, apperror.NewErrorForClient(errorTypeInvalidProductUserName, "productUserName cannot be empty") } maxLengthProductUserName := 255 if len(value) > maxLengthProductUserName { return nil, apperror.NewErrorForClient(errorTypeInvalidProductUserName, "invalid productUserName") } return &ProductUserName{value: value}, nil } func (n ProductUserName) String() string { return n.name }
- Enumによる型制約(例:SiteType)
サービスの種類や表示先のように「取りうる値が限定されているケース」では、Enum型を使って表現しました。 これにより、画面入力などで不正な文字列が直接渡ってくることを防ぎ、使用箇所では正しい型だけが使われる保証が得られます。
const ( SiteTypeServiceAID = 1 SiteTypeServiceBID = 2 ) var ( siteTypeToID = map[string]int{ "service_a": SiteTypeServiceAID, "service_b": SiteTypeServiceBID, } idToSiteType = map[int]string{ SiteTypeServiceAID: "service_a", SiteTypeServiceBID: "service_b", } ) type SiteType struct { id int } func NewSiteType(siteType string) (*SiteType, error) { siteTypeID, ok := siteTypeToID[siteType] if !ok { return nil, apperror.NewErrorForClient(errTypeInvalidSiteType, fmt.Sprintf("siteType: %s", siteType)) } return &SiteType{id: siteTypeID}, nil }
2.イベントから実装への変換プロセス
「告知を公開した」「記事を公開した」などのイベントは、実装ではそれぞれの状態変化・保存処理として表現されました。
状態変化をもってイベントが起きたことを示す構造で、ドメイン層の操作が「意味ある出来事」に結びつく形となっています。
イベントストーミング図に示された制約(「初回公開の場合のみfirstPublishedAtを設定する」「下書き記事が存在する場合、下書き記事を公開」など)は、すべてドメインモデルのロジックに取り込まれています。
※「下書き記事を削除した」などの特に制約がないイベントの場合、そのまま下書き記事IDで削除すればいいのでイベントへの変換作業はありません。
// 告知公開 func (a *Announcement) Publish(updateProductUser ProductUserName, draftArticle *DraftArticle) (*Article, error) { a.lastUpdateProductUserName = name now := time.Now() // 初回公開の場合のみfirstPublishedAtを設定する if a.firstPublishedAt == nil { a.firstPublishedAt = &now } // 告知公開 a.lastPublishedAt = &now // 下書き記事が存在する場合、下書き記事を公開 if draftArticle != nil { if draftArticle.effectedRange != nil { a.closedAt = draftArticle.effectedRange.effectedEnd } article, publishErr := draftArticle.publish(a.id) if publishErr != nil { return nil, apperror.WrapError(errTypeFailedToPublishResource, publishErr) } return article, nil } return nil, nil } // 記事公開 func (d *DraftArticle) publish(announcementID int) (*Article, error) { return NewArticle(announcementID, d.serviceTagIDs, d.title, d.content, d.effectedService, d.effectedRange) }
3. コマンド から実装への変換プロセス
 イベントストーミング上の「記事を公開する」はコマンドに相当し、これは ユースケース層のメソッドに対応します。
今回はpublishAnnouncementUseCase.Execute() というメソッドを用意しました。
イベントストーミング上の「記事を公開する」はコマンドに相当し、これは ユースケース層のメソッドに対応します。
今回はpublishAnnouncementUseCase.Execute() というメソッドを用意しました。
コマンドの責務は、ユースケースの一貫した処理を組み立てることです。ドメイン層の Publish を呼び、発生した副産物( 公開した Articleなど)を保存します。
func (u *publishAnnouncementUseCase) Execute(ctx context.Context, announcementID int, updater string, updatedAt time.Time) (*PublishDTO, error) { announcement, getAnnouncementErr := u.announcementRepository.GetByID(ctx, announcementID) if getAnnouncementErr != nil { return nil, apperror.WrapError(usecase.ErrTypeFailedToGetResource, getAnnouncementErr) } if announcement == nil { return nil, apperror.NewErrorForClient(apperror.ErrTypeNotFoundResource, "announcement not found") } updateProductUserName, productUserNameErr := model.NewProductUserName(updater) if productUserNameErr != nil { return nil, apperror.WrapError(errTypeNewProductUserName, productUserNameErr) } draftArticle, getDraftArticleErr := u.draftArticleRepository.GetByAnnouncementID(ctx, announcementID) if getDraftArticleErr != nil { return nil, apperror.WrapError(usecase.ErrTypeFailedToGetResource, getDraftArticleErr) } publishArticle, publishAnnouncementErr := announcement.Publish(*updateProductUserName, draftArticle) if publishAnnouncementErr != nil { return nil, apperror.WrapError(errTypeFailedToPublishResource, publishAnnouncementErr) } dto := &PublishDTO{} transactionErr := u.dbConnection.WriterDB.Transaction(func(tx *gorm.DB) error { updatedAnnouncmment, updateAnnouncementErr := u.announcementRepository.Update(ctx, announcement, updatedAt, db.WithTx(tx)) if updateAnnouncementErr != nil { return apperror.WrapError(usecase.ErrTypeFailedToUpdateResource, updateAnnouncementErr) } dto.UpdatedAt = updatedAnnouncmment.UpdatedAt() if publishArticle == nil { return nil } updateArticleErr := u.articleRepository.UpdateByAnnouncementID(ctx, *publishArticle, db.WithTx(tx)) if updateArticleErr != nil { return apperror.WrapError(usecase.ErrTypeFailedToUpdateResource, updateArticleErr) } deleteErr := u.draftArticleRepository.Delete(ctx, draftArticle.ID(), db.WithTx(tx)) if deleteErr != nil { return apperror.WrapError(usecase.ErrTypeFailedToDeleteResource, deleteErr) } return nil }) if transactionErr != nil { return nil, transactionErr } return dto, nil }
4. 実装とイベントストーミングとの違いの見直しと仕様変更による修正
前回の記事も述べたように、ドメインモデリングは一回で終わりません。仕様の変更や実装の途中で「制約を追加した方がいいかも」「こういうモデルが必要かも」と気付くことがあります。その場合はイベントストーミング〜制約の見直しの工程に戻り修正します。
イベントストーミングでは、業務的に重要なイベント(例:記事を公開した、下書きを削除した)を明示的に扱っていましたが、実装では状態遷移を中心とした表現で処理されています。 実装しているうえでイベントストーミングと違いが発生するかもしれません。
たとえば最初のイベントストーミングでは「ProductUser(ValueObject)」がありましたが、見直した後の実装ではProductUserNameにしています。
理由としては作成/更新者の名前だけを保存するのでProductUserNameが正しいということで修正しました。

他にも仕様変更による公開のイベントストーミングの修正がありました。 例として、「公開する場合、承認が必要な機能を導入する」という仕様変更があるとしましょう。
※ 承認する/承認取り消し機能のイベントストーミングの追加も必要ですが、ここでは省略して機能追加による仕様変更の流れとさせていただきます。
Announcement(Aggregate)に ApproverStaffID を追加し、公開イベントにもチェックが追加されます。
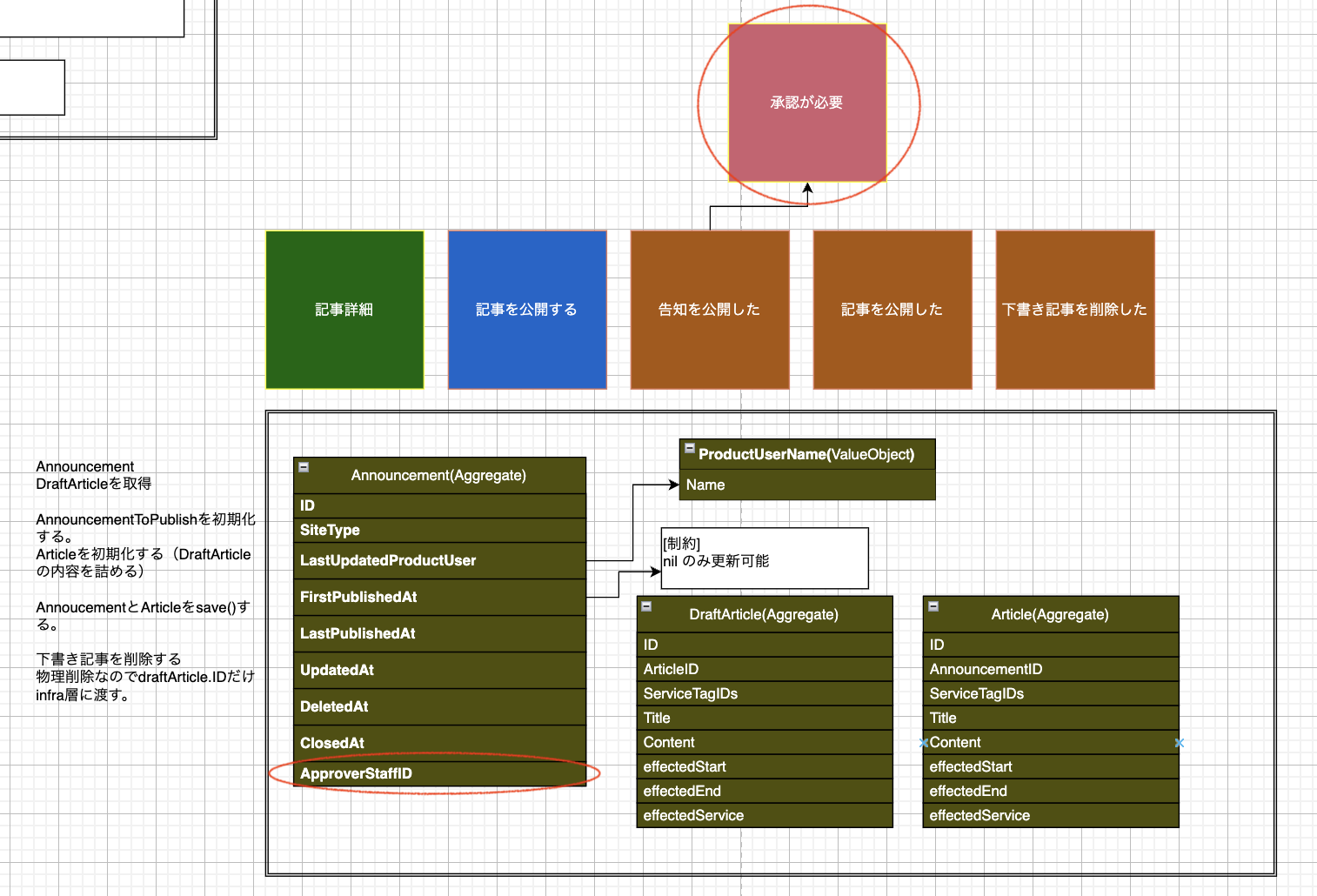 そして該当のコードを修正します。
そして該当のコードを修正します。
type Announcement struct { id int siteType SiteType lastUpdatedProductUser ProductUserName firstPublishedAt *time.Time lastPublishedAt *time.Time closedAt *time.Time ApproverStaffID *int // ApproverStaffID 追加 ... } // 告知公開 func (a *Announcement) Publish(updateProductUser ProductUserName, draftArticle *DraftArticle) (*Article, error) { if a.ApproverStaffID == nil { // 承認済かどうかの確認 return nil, apperror.WrapError(errTypeNotApproved, fmt.Errorf("approver staff ID is required for publishing")) } // ...(以降の処理は変わらず) }
このように、設計は一度決めて終わりではなく、実装を通じて明らかになる要件や仕様の変化に応じて、継続的に見直していくことが重要だとあらためて実感しました。 ※ Infrastructure層の修正は省略しています。
テストしやすい制約のポイント
制約をドメインロジックやValueObjectに閉じ込めることで、ユニットテストの単位が明確になり、テスト対象が細かく分離されました。 たとえば NewProductUserName("") のように、異常系のテストをValueObject単体で完結させられるため、UseCaseやHandlerのテストでは「正常系に集中する」設計が可能になります。 また、制約の追加や変更が必要になった場合でも、集中管理されているため変更漏れや影響調査がしやすく、保守性の高い構造が実現できました。
テスト戦略の変化
テストの容易さは、設計の健全さを映す鏡と言えます。 以前は、カバレッジを満たすこと自体が目的になってしまい、「動いてさえいればOK」という感覚で書かれたテストも少なくありませんでした。 しかし戦略的DDDを取り入れ、責任の単位ごとにロジックが整理されたことで、本質的な意味を持つテストを書くことができるようになりました。 ドメイン層ではユニットテストでロジックの正しさを厳密に検証し、アプリケーション層では統合テストでユースケース全体の流れを確認。モックやスタブも役割ごとに整理され、テストコードの保守性も格段に上がりました。 さらに、CI環境(GitHub Actions)におけるテスト時間も短縮され、変更からマージまでのフロー全体が軽く、速くなったことを実感しています。 この章では、私たちのテスト戦略がどのように変化したのかをご紹介します。
ユニットテストと統合テストの責任分離
設計の見直しにより、ドメイン層・アプリケーション層の責任が明確になったことで、それぞれに適したテスト戦略を取れるようになりました。
リアーキテクト前は、service層がドメインロジック、外部アクセス、ユースケース制御などをすべて内包していたため、ユニットテストを書く際にもモックやテストデータの準備が煩雑で、「本当に検証したいロジック」に集中できないことが課題でした。
一方、リアーキテクト後は責務が分かれたことで、次のようにテスト単位を明確に整理できました:
- ドメイン層(Entity, ValueObject, DomainServiceなど)
→ ロジックや制約の単体検証を目的としたユニットテストを記述。外部依存がないため高速かつ安定して実行可能。
- UseCase層(アプリケーションの処理フロー)
→ スタブやモックを使って、ユースケースの統合的な振る舞いを確認。たとえば「公開可能か判定→記事生成→保存→下書き削除」といった一連の流れを1つのテストで保証。
この分離により、テストの意図・粒度・失敗原因が明確になり、読みやすく・保守しやすい構成が実現しました。
また、テストコード自体もドキュメントのように振る舞いを説明できるようになり、レビューの質も上がったと感じています。
モック・スタブ戦略の明示
リアーキテクト前は、service層がビジネスロジックと一緒に dao層を直接呼び出していたため、ユースケース単位でのテストにおいて、どこをスタブにし、どこまでを実行対象とすべきかが曖昧になりがちでした。dao層自体は Interface によって抽象化され、モックの導入も可能でしたが、下記の問題があります。
- モックを使う範囲が広くなり、テストコードの見通しが悪化
- テスト対象が1メソッドのみに絞れず、結果として、余計な振る舞いのスタブ定義が必要になる
- 明確な責務境界がなかったため、結果として、実DBを使ったテストが現実的選択肢になることも多かった
リアーキテクト後は、Infrastructure層として I/O 処理を明確に切り出し、UseCase 層はリポジトリインターフェース越しにやりとりする形に統一しました。
- UseCase層のテストは、Repository Interface に対して明示的にモック・スタブを注入
- Domain層のテストはロジックのみに集中し、モック不要
- Infrastructure層の実装は別途統合テストやE2Eテストでカバー
この戦略により、「どのレイヤーのテストで何を使うか」が整理され、テスト戦略がチーム内共有可能な形で確立されました。
「壊れやすい構造」から 「テストしやすい構造」 へどう変わったか
従来の service 層中心の構造では、責務が混在していたためユニットテストの対象が不明瞭で、「テストを書こうとすると全部モックする必要がある」といった問題がありました。
DDDベースの構造に移行してからは、責任が分離されているため、下記のようにテスト対象が層単位で完結するようになりました。
- 1ユースケースのテストはUseCase層で閉じる
- ロジックの検証はドメイン層のユニットテストで済む
- I/Oや副作用を含む処理はInfrastructure層で明示的にカバーされる
結果として、壊れても直しやすく、壊れにくい構造に進化したと実感しています。
設計を「知識」として蓄積する
リアーキテクト以前の開発では、ある程度要件をまとめているものの、「実装しながら設計する」ことが当たり前になっていました。 しかしDDDやドメインモデリングの導入によって、私たちの開発プロセスには「実装の前に設計が発生する」という明確なステップが生まれました。
その結果、ユースケースやモデルに対する設計の意図が、図やドキュメントといった 「見える形の知識」 として自然と残るようになりました。 これらは単なる設計資料ではなく、「再利用できるチームの共通言語」として活用されています。
私たちは、こうした設計知識をチームに蓄積し、誰が見ても理解しやすく、レビューや議論の前提となる文化を大切にしています。 この積み重ねが、継続的に進化できるプロダクトの礎になると信じています。
この章では、設計をどのようにチームの知識として蓄積・共有しているかを解説します。
各層の責任の明確化とそれによるレビュー・開発体験の変化
DDDの導入によって、アーキテクチャ全体の構造が明確に整理されました。その結果として、以下のような開発上の変化を実感しています:
レビューの観点が明確になった
- 「これはドメイン層のロジックとして正しいか?」
- 「ユースケースとインフラが適切に分離されているか?」
- 「読み物ではなくチェックとしてレビューしやすくなった」
影響範囲の特定が容易になった
- たとえば Entity の変更はドメイン層に限定されるため、PRの変更差分の把握がスムーズ
- UseCase のテストだけで完結するケースも増え、局所的な修正・確認が可能になった
PR粒度が自然と小さくなった
- 層ごとに責務が限定されているため、1PRで多くの層にまたがることが減り、レビュアーの負担も軽減
- 結果として PR のスループットが上がり、Findy Team+ スコアの改善にも寄与
AIツールの補完・レビュー支援との相性が良くなった
- Devin や Copilot の支援を受けた際、層単位での指摘や提案の精度が上がった
- 「この修正はUseCaseの話」「これはEntityの責務だ」といった分類がツールにも理解されやすくなった
数値で示す改善
前回の記事でも触れたましたが、リアーキテクト後の私たちの開発スコアには明確な改善が見られました では、具体的に何を変えたことが、このスコアの向上に繋がったのでしょうか? 本章では、DDDやドメインモデリングの実践を通じて「どのような開発プロセスの変化があったのか」、それが「どうスコアに現れたのか」を振り返ります。
Findy Team+ PR数値スコア向上
※内容は前回記事内容の再掲になります。 前期間(リアーキテクト前): 2024年5月22 - 2024年11月21日。 現期間(リアーキテクト後): 2024年11月22 - 2025年5月21日。
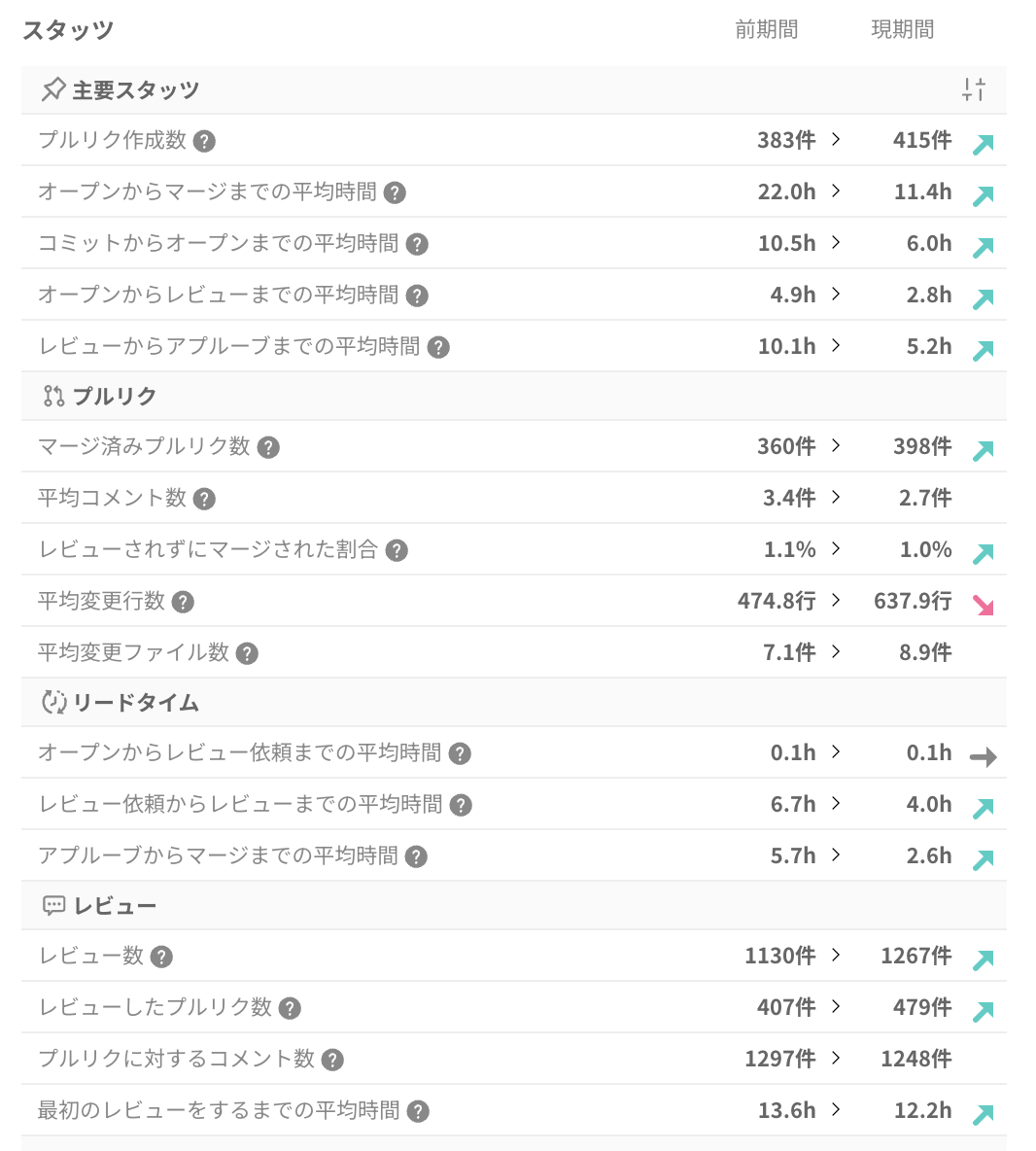
プルリクエスト数とスループットの比較
| 指標 | リアーキテクト前 (2024/5/22–11/21) |
リアーキテクト後 (2024/11/22–2025/5/21) |
変化量 |
|---|---|---|---|
| プルリク作成数 | 383 件 | 415 件 | 約8% 増 |
| マージ済みプルリク数 | 360 件 | 398 件 | 約11% 増 |
開発チーム全体でプルリクエストの作成数・マージ数が増加しており、スループット(開発生産性)が向上していることが分かります。
サイクルタイムの比較
| フェーズ区間 | Before(時間) | After(時間) | 短縮率 |
|---|---|---|---|
| Open → Merge | 22.0 | 11.4 | 約 93% 短縮 |
| Commit → Open | 10.5 | 6.0 | 約 43% 短縮 |
| Open → Review | 4.9 | 2.8 | 約 43% 短縮 |
| Review → Approve | 10.1 | 5.2 | 約 49% 短縮 |
各フェーズで平均所要時間が大幅に短縮されており、特に Open → Merge は半分以下になっています。これにより、レビューからマージまでの開発リードタイムが、効率化されたことが見て取れます。
これは層単位での粒度の細かいPR設計により、コミットの変更が小さくなり、レビューがしやすくなったためです。
CI時間が短縮(GitHub Actions)
これはテスト戦略の変化ユニットテストと統合テストを明確に分けたことにより、ユニットテストでは Dockerの立ち上げやDBへの接続が無くなったためです。 CI時間は、リアーキテクト前の十数分〜数十分から数分に短縮されました。
モデリング/設計ノート/図(draw.io等)を残す・共有する文化を追加
モデリングの際に使用したイベントストーミング図やドメインモデル図は、単にその場の議論で終わらせるのではなく、都度見返せるようにdraw.ioなどで清書しています。
これにより、「なぜこのモデル構造になっているのか」「どのような状態遷移があるのか」といった背景を、実装者以外も追跡できるようになりました。
また、図をレビューや仕様調整の材料として再利用することも多く、「使い捨てではない設計資産」として定着しています。
コードレビュー時の観点チェックリスト
設計の意図がコードに反映されているかを確認するために、レビューでは「どの層の責務か?」や「これはドメイン知識か?それともアプリケーション制御か?」といった観点を共有し、活用しています。
明文化されたルールに加え、過去のレビューで繰り返し議論になった点は、チェックリストやガイドとしてdraw.ioなどに残すようにしています。
これにより、新しい実装者やレビュアーでも、同じ視点で品質の議論ができる仕組みが整いました。
新メンバー向けドメイン理解資料の整備
新しく入ったメンバーがドメインの背景やモデル構造を理解しやすくするため、各機能の背景・設計意図・制約をまとめた設計ノートを整備しています。
これはドキュメント単体ではなく、実際のコード構造・ストーリーベースの流れに沿った資料として構成されており、実装に携わる前に読むことで「どう考えてこの形になったか」が理解できるようになります。
設計の属人性を減らし、継続的に設計文化を引き継いでいける土台として機能しています。
まとめと今後の展望
DDD導入の成果は、チームの文化にも影響を与えました。 設計力の向上、レビューの質の変化、そしてAI導入など未来の技術に対して自然に向き合えるチーム文化が生まれつつあります。 今回ご紹介した実践の数々は、決して一足飛びに実現できたものではありません。 試行錯誤を繰り返しながら、設計・実装・文化が互いに影響しあう中で、少しずつ形になってきたものです。 今後はさらに、AIを活用したドメイン駆動開発の高度化にも取り組んでいく予定です。
チームの設計力向上
DDD導入以降、チーム全体で「設計とは何か?」を言語化・共有しながら取り組む文化が定着し始めています。
レビューでは「この責務はドメインか?ユースケースか?」といった議論が自然に行われるようになり、実装方針や設計判断がチームで説明・議論できる環境が整いました。
また、メンバーごとの設計レベルのばらつきが減少し、チーム全体の思考の粒度やモデルへの感度が底上げされたと感じています。
AIを含む外部連携や業務効率化の加速可能性
アーキテクチャの明確化と構造の分離により、AIや外部サービスとの接続ポイントが把握しやすくなり、実験・導入のハードルが大きく下がりました。
すでにCodeRabbitによるPR要約支援などが導入済みで、レビュー効率が改善されています。
今後はDevin等を活用した設計意図の補完やドメイン知識の対話的引き出しといった支援も視野に入れ、AIと開発者が補完しあう開発環境の構築を目指しています。
設計改善の結果による「AI導入しやすい構造」の土台づくり
もともと「AI導入しやすい構造」の土台づくりが目的ではありませんでした。しかしDDDを導入してから、構造が明確になったことで「AIが活用しやすいコードベース」が生まれました。
DDD導入による利点:
各層の責任が明確になり、設計の意図がコード構成から自然に読み取れるようになりました。
その結果、DevinのようなAI開発支援ツールを活用しても、補完候補や生成されたコードの位置づけを正しく理解・適用しやすくなりました。AI活用の支援効果:
実装中にDevinを使って関数の提案や既存コードの解説を受けた際、以前よりもその情報の信頼度や「コード全体との整合性」を確認しやすくなりました。
DDDでの責務整理やユースケースの明確化が、AIツールの支援品質を高めたと感じています。Pull Requestレビュー支援:
CodeRabbit などプルリクレビュー支援ツールの精度向上が期待できます。
設計が整っていることで、AIが生成するコメントや変更要約の精度も高く保たれており、実際の開発現場で大きな効果を感じています。今後の可能性:
- 実装支援とレビュー支援の連携強化
- 影響範囲を踏まえた自動テスト候補提示などへの展開
将来的に挑戦したいAI応用(自動要約、分類など)の構想
蓄積された設計情報・設計文脈をもとに、次のステップとして以下のような応用にも挑戦したいと考えています:
- PR・ドメインモデルの自動要約や説明補助
- 設計に対するIssueやトラブルの自動起票
- 複雑な業務フローの分類・影響範囲の自動分析
これらを実現するには、設計が「構造的にただしくある」ことが前提になります。今後も設計を軸としたAI活用の高度化にチャレンジし続けます。
宣伝
ここまで読んでいただきありがとうございました!
私たちCSPグループではDDDをはじめ新たな設計手法の導入、AIを活用した開発と業務改善などを行い、プロダクトの開発に取り組んでいます。
専門性の高いメンバー(時には他部署のエンジニアやマネージャーとも)協力しながら、自らのアイデアを実装し、ユーザー満足度向上を追求できる環境です。
チームとプロダクトの成長を支える一員として一緒に活動していきませんか?
少しでも興味がある方はぜひ下記採用ページをご確認ください。 dmm-corp.com