

DDD経験者がEvent Sourcingで躓いた話
はじめに
DMMのプラットフォーム開発本部/第2開発部で決済領域を担当している田島一生です。 DMMに入社してまだ2ヶ月ほどの新参者ですが、決済プラットフォームのモダナイゼーションに携わるチームにjoinし、そこで感じた迷いを共有しておきます。後続の人が同じ壁に当たらないように、私がやった学習の流れや気づきをまとめました。
1. 背景
私はこれまで DDD(ドメイン駆動設計)/クリーンアーキテクチャ中心のモノリス開発をメインに経験してきました。 今回、決済プラットフォームのモダナイゼーションで購入領域に途中参加したのですが、コードベースは Event Sourcing と Temporal を前提とした分散システムとして設計されていました。
決済領域では外部システム連携(決済代行など)が不可欠であり、ネットワーク障害や処理遅延の発生リスクは常に存在します。 そのため結果整合性を前提とし、各ステップの再実行可能性と冪等性を保証する必要があります。このようなニーズから、Event Sourcingによる状態管理と、Temporalを使った非同期オーケストレーションが採用されています。
ただ、Event Sourcing も Temporal も概念としては知っていたものの、実装や運用の具体的なイメージが掴めず、かなり苦戦しました。そこで、後続の新規参入者でも再現できるよう、購入フローの最小チュートリアル(Go + Temporal)を自作して動かし、理解をコードレベルで固めたのが本記事の出発点です。
何が変わったのか(対比表)
私が直面した違いを、4つの対比軸で整理すると以下のようになります:
| 対比軸 | 従来の経験 | 今回の環境 |
|---|---|---|
| システムアーキテクチャ | モノリス (一枚岩な構造) |
分散システム (複数サービス連携) |
| 状態永続化モデル | State Sourcing (最新状態を保存) |
Event Sourcing (イベント履歴を保存) |
| 処理制御モデル | 同期的処理 (単一プロセス完結) |
非同期オーケストレーション (分散処理制御) |
| 障害時の対応 | ロールバック | Saga(補償処理) |
本記事では、特に状態永続化モデルと処理制御モデルの2つの大きな違いについて、私が躓いたポイントと学んだことを共有します。
2. 私が直面した2つの大きな違い
2-1. 大きな違い①:状態永続化モデル
私はこれまでモノリスでのDDD/クリーンアーキテクチャを経験してきました。そこから決済プラットフォームに参加して、一番の違いは「何を保存するか、どう復元するか」でした。
State Sourcing(従来の方法)
- API → UseCase → 集約(Aggregate)が同一プロセスで完結
- 集約の最新状態をDBに保存
- 障害時はロールバックで巻き戻し
Event Sourcing(今回の現場での方法)
- 集約の状態ではなく、イベント履歴を保存
- EventStore(イベント+Snapshot)から都度復元
- Snapshotはパフォーマンス最適化のため
私がつまずいたポイント
これまでモノリス(もしくは分散モノリス)でDDDを実践してきた私にとって、最初に戸惑ったのは「イベント」の扱い方でした。DDD には「ドメインイベント」という概念がありますが、私自身は以下のような軽い使い方しかしてきませんでした:
- sealed class で状態を分ける程度
- イベント通知(ドメインイベントを発行して、別の集約に通知する)
- せいぜいイベント的な状態を別テーブルに保存して監査目的として残す程度
EventStore を中心とした設計(Event Sourcing)は扱ってきませんでした。
つまり、「イベントという概念は知っている」が、「イベントから状態を復元する」「集約はイベントの積み重ねである」という考え方には馴染みがなく、ここが大きな壁になっていたと思います。
Event Sourcing での「何を保存するか」
Event Sourcing を学ぶうえで、私が最初に混乱したのは何を保存するのかでした。
私が陥った誤解
処理の各ステップが終わるたびに、その時点の集約インスタンス(状態)を都度保存すると思っていました。 また、Snapshot が何のために存在するのかもよく分かっていませんでした。
実際の仕組み
チュートリアルを実装して理解できたのは、以下の点です:
保存するもの:
- イベント(Journal):何が起きたかの履歴を append-only で保存
- Snapshot:ある時点の集約の状態を直列化したもの
集約の扱い:
- 集約インスタンス自体は永続化しません。処理の各ステップが終わると集約は破棄されます
- 次のステップでは、EventStore から復元処理を毎回行う必要があります
Snapshot の役割:
- イベントが膨大になると、全イベントの復元は遅くなります
- Snapshot があれば「Snapshot時点の状態 + それ以降のイベント」だけで高速に復元できます
つまり、イベントが事実、Snapshot はパフォーマンス最適化という整理ができました。
なぜ Snapshot だけではダメなのか(なぜイベントも必要か)
「集約の最新状態(Snapshot)だけ保存すれば良いのでは?」という疑問が湧きますが、 コストとパフォーマンスの問題 があると考えました。
本番環境では、Snapshot を毎回保存すると、次のような問題が生じます:
- 書き込みコストが高い:ストレージへの書き込み回数が増える
- 書き込み処理が重い:Snapshot(集約全体の状態)はイベント(差分)より大きいデータ
そこで、一定間隔(例:10イベントごと)でのみ Snapshot を保存する戦略を取ります。
イベント1 → Snapshot保存 イベント2 → イベントのみ保存 イベント3 → イベントのみ保存 ... イベント10 → イベントのみ保存 イベント11 → Snapshot保存 ← 10回に1回だけ
この場合、最新のSnapshotを取得しても、それは少し古い状態です。 そのため、その後のイベントをリプレイして最新状態に復元する必要があります。
これが Event Sourcing のスナップショット最適化パターンです。後述のコード例で、この復元処理(GetLatestSnapshotById() と ApplyEvent())の実装を詳しく説明します。
2-2. 大きな違い②:処理制御モデル
もう一つの違いは「処理の流れをどう制御するか」でした。
同期的処理(従来の方法)
- API → UseCase → Aggregate が同一プロセスで完結
- 処理が完了するまでレスポンスを返さない
Temporalによる非同期オーケストレーション(今回の現場での方法)
- APIはWorkflowを起動するだけ(すぐにレスポンスを返す)
- Workflow(処理の流れ)/Activity(各処理ステップ)が別プロセスで実行
- 各ステップで状態を復元する必要がある
私がつまずいたポイント
まず、Temporalを使った処理全体の流れがイメージできませんでした。
Temporal とは:複数のステップからなる処理(ワークフロー)を確実に実行するためのオーケストレーションエンジンです。途中で失敗しても、自動リトライや処理の再開ができます。
実際の処理の流れは以下の通りです:
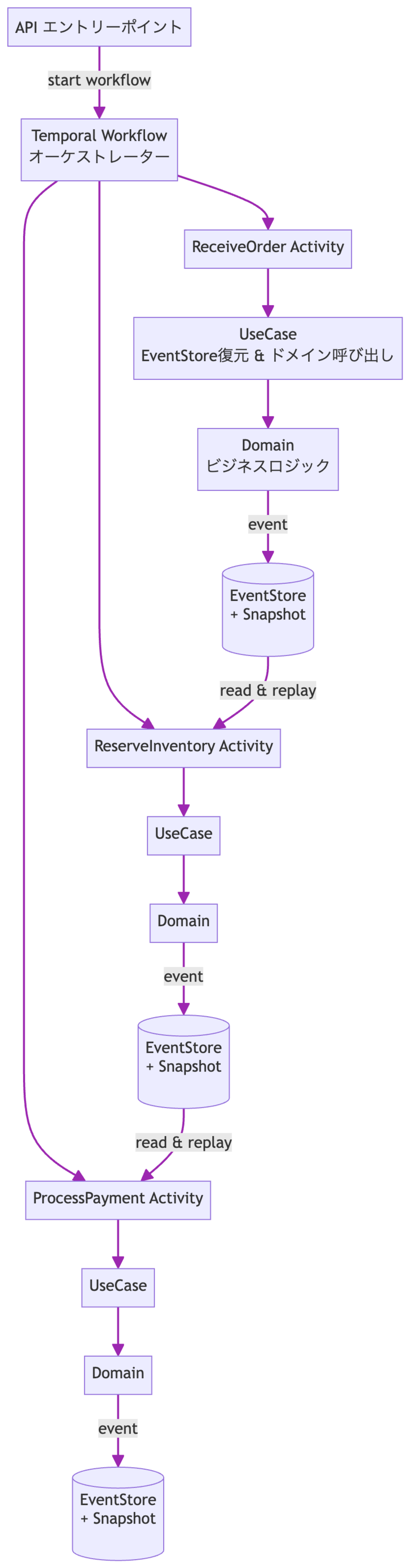
この流れを理解したうえで、各層の責務を整理すると次のようになります:
- Workflow:処理のオーケストレーター(順序・RetryPolicy・タイムアウト)。
- Activity:実際に処理を実行する単位(EventStore書き込み、外部API呼び出しなど)。別プロセスで実行され、リトライ可能。
- UseCase(Application層):EventStoreやドメインオブジェクトを組み立てる層。Activity の内部から呼ばれる。
つまり Activity は「ユースケースそのもの」ではなく、ワークフローのステップです。 Activity/Workflow が「リトライ、タイムアウト、補償(Saga)、トランザクション境界」を担い、UseCase はEventStoreから集約を復元してドメインメソッドを呼び出す、という責務分離を意識すると実装が理解できてきました。
3. ミニチュートリアルの実装(要点とコード抜粋)
理解を深めるため、購入から決済までの一連のフローを題材にした最小実装を作りました。 目的は半日で動く最小実装(正常系)で、手で動かして腑に落とすことです。
フロー(正常系)
PurchaseInitialized -> OrderReceived -> InventoryReserved -> PaymentProcessed -> PurchaseCompleted
Workflow(オーケストレーター)
Workflow は複数の Activity を順番に実行するオーケストレーターです。 各 Activity が成功するまで自動でリトライし、全体の処理フローを確実に実行します。
workflow.ExecuteActivity(ctx, "ReceiveOrderActivity", ...) workflow.ExecuteActivity(ctx, "ReserveInventoryActivity", ...) workflow.ExecuteActivity(ctx, "ProcessPaymentActivity", ...) workflow.ExecuteActivity(ctx, "CompletePurchaseActivity", ...)
Activity での処理(復元 → 実行 → 保存)
各 Activity は「EventStoreから復元 → ドメインメソッド実行 → EventStoreへ保存」というサイクルを繰り返します。 これが Event Sourcing + Temporal の基本パターンです。
// 1. Snapshot から集約を復元 result, err := a.store.GetLatestSnapshotById(ctx, &purchaseID) if err != nil { return err } purchase := result.Aggregate.(domain.Purchase) // 2. 復元した集約に対してドメインメソッドを実行 event, newState, err := purchase.ReserveInventory() if err != nil { return err } // 3. イベントと新しい状態を保存 if err := a.store.PersistEventAndSnapshot(ctx, event, newState); err != nil { return err }
GetLatestSnapshotById() で前の Activity で保存した Snapshot から集約を復元します。
このチュートリアルでは理解しやすさを優先して毎回Snapshotを保存する実装にしています。
本番環境では、前述のように一定間隔(例:10イベントごと)での保存に最適化します。その場合、GetLatestSnapshotById() で取得したSnapshotは少し古い状態なので、後述の ApplyEvent() メソッドを使って、Snapshot以降のイベントを順番にリプレイして最新状態に復元します。この2つのメソッドの組み合わせがEvent Sourcingの復元パターンの肝だと思います。
ドメインメソッドを実行してイベントと新しい状態を生成し、PersistEventAndSnapshot() で保存します。
イベント(履歴)を保存することで処理の冪等性を保証し、Snapshot(最新状態)を保存することで次のActivityでの高速な復元を可能にします。
イベント構造
イベントは「何が起きたか」を表す不変のデータです。各イベントには購入ID(PurchaseID)、シーケンス番号(SeqNr)、そしてそのイベント固有のデータ(商品ID、数量、金額など)が含まれます。
type PurchaseOrderedEvent struct { PurchaseEventMeta ProductID ProductID Quantity Quantity Amount Money } func NewPurchaseOrderedEvent(purchaseID PurchaseID, seqNr uint64, productID ProductID, quantity Quantity, amount Money) *PurchaseOrderedEvent { return &PurchaseOrderedEvent{ PurchaseEventMeta: newPurchaseEventMeta(purchaseID, seqNr), ProductID: productID, Quantity: quantity, Amount: amount, } }
ApplyEvent(状態復元の肝)
Activity が別プロセスで実行されるため、毎回EventStoreからイベントを取得して集約を復元する必要があります。
ApplyEvent() は、保存されたイベントから次の状態へ遷移させるメソッドです。例えば、InitializedPurchase に PurchaseOrderedEvent を適用すると OrderedPurchase に遷移します。
func (p *InitializedPurchase) ApplyEvent(event eventstore.Event) eventstore.Aggregate { switch e := event.(type) { case *PurchaseOrderedEvent: return &OrderedPurchase{ PurchaseMeta: newPurchaseMeta(e.PurchaseID, e.SeqNr), ProductID: e.ProductID, Quantity: e.Quantity, Amount: e.Amount, } default: panic(fmt.Sprintf("unexpected event: %T", event)) } }
4. まとめ
本記事では、2つの大きな違いについて説明しました:
①状態永続化モデル(State Sourcing → Event Sourcing)
- イベント履歴が事実、Snapshotはパフォーマンス最適化
- 集約は都度復元する必要がある
- 監査可能性と再実行可能性を実現
②処理制御モデル(同期的処理 → Temporalによる非同期オーケストレーション)
- Workflowがオーケストレーター、Activityが各ステップ
- リトライ、タイムアウト、補償(Saga)を自動化
- 結果整合性を保証
このチュートリアルを実装することで、上記の違いが腑に落ちました。特に、読むだけでは概念的なノリで終わっていたものが、実際にコードを動かすことで概念と実装が繋がりました。
振り返って
最初はモノリス脳のままコードを読んで頭が混乱してしまいましたが、実際に手を動かしてイベントを保存→復元する体験を得ることで理解を深めることができました。
振り返ってみると、モノリスでDDDを経験していたからこそ逆に混乱した部分もあったように思います。 「集約の現在の状態が全て」という染み付いた感覚が、Event Sourcing の理解を混乱させていました。 もしかすると、DDDの経験がない人のほうが、先入観なくこのアーキテクチャをスッと受け入れられるかもしれません。 固定観念にとらわれず、新しいアーキテクチャを素直に受け入れる姿勢が重要だと痛感した経験でした。 この記事が、これから Event Sourcing に取り組む人の助けになれば幸いです。
決済領域では複数のステップにまたがる整合性を保つ必要があり、Event Sourcing + Temporal の組み合せはこれを確実に保つ強力な仕組みです。 決済領域であってもこのようなしっかりした分散システムを構築できる経験は、なかなかありません。 第2開発部では、決済プラットフォームのモダナイゼーションに一緒に取り組んでいただけるメンバーを募集しています! 興味を持っていただけた方は、ぜひご応募ください! dmm-corp.com