

1. はじめに
こんにちは、プラットフォーム開発本部CSPグループの佐々木です。
私たちのチームでは、ここ半年ほどAIを開発フローに本格的に組み込んできました。 当初は「AIに任せればなんでも楽ができる」と期待していましたが、実際にやってみると、ただ漫然と使うだけでは意図しないコードが生成されたり、逆に人間のレビュー負担が増えるといった課題も見えてきました。
この記事では、試行錯誤の末にたどり着いた「ドキュメントとルールをベースにしたAI活用」の具体的な手法と、それによって得られた成果(工数半減・デプロイ頻度向上)、そして直面したリアルな課題について備忘録として書き残します。
AIを単なるコーディングアシスタントとしてだけでなく、開発プロセス全体を加速させるパートナーとしてどう組み込んでいくか。そのヒントになれば幸いです。
2. 開発フローの全体像
私たちのチームの開発フローと、各工程でAIをどのように活用しているかの概要は以下の通りです。
1. PRD作成(AI活用は検証中)
- 何を・なぜ作るのかを整理する
2. DesignDoc作成(AI活用は検証中)
- どう実現するかを技術的に設計する
3. API定義書・DB定義書作成 ← AIで楽になった
- エンドポイントやテーブル定義を具体化する
4. ドメインモデリング ← AIで楽になった
- ビジネスルールをドメインモデルに落とし込む
5. 実装 ← AIで楽になった
- Usecase層・API層・インフラ層のコード作成
6. 検証 ← AIで楽になった
- APIテストや動作確認
上流工程(PRD・DesignDoc)はAI活用を検証中
PRDやDesignDocといった上流工程については、AI活用はまだ手探りの状態です。
これらの工程では、多くのステークホルダーとの調整や、UI/UXに関する発散的な議論、高い抽象度での意思決定が必要となります。そのため、AIに渡すための明確な「ルール」や「正解」を定義しきれないのが現状です。
逆に言えば、この上流工程で仕様をしっかりと固めることができれば、以降の工程はAIによって劇的に効率化できることが分かってきました。そのため、本記事では仕様が固まった後の「3. API定義書作成」以降の工程に焦点を当てて解説します。
AI活用のアプローチ:Cursorと「ルール」
具体的なAI活用のアプローチとして、私たちのチームでは主に Cursor を使用しています。
特徴的なのは、各開発工程(API定義、ドメインモデリング、実装など)ごとに、守るべき規約や設計思想をまとめた「ルール」をマークダウン形式で用意している点です。
AIに作業を依頼する際は、単に指示を出すのではなく、主に以下のようなルールを渡します。
- インプットとなるドキュメント(PRDやDesignDoc)
- 従うべきルール(Markdown形式の規約)
例えば5章の実装部分で後述するUsecase層の実装ルールについて下記のような形式となります。(どんな感じのマークダウンファイルを作っているのかのイメージとして参照していただけると助かります。)
---
description:
globs:
alwaysApply: false
---
### 設計要件
以下を全て満たすこと
- 構造体であること
- 名前は「ビジネスユースケース名 + UseCase」であること
- 例:「ユーザーアカウントを登録する」というビジネスユースケースの場合、RegisterUserAccountUseCase
- ビジネスユースケースと1:1であること
- ファイルの置き場所:Usecase層の役割を持つフォルダ
## 概要
DDDアーキテクチャにおけるusecase層の実装ルール。
アプリケーションロジックを実装し、ドメインモデルとインフラストラクチャを組み合わせてビジネスユースケースを実現する。
## 基本ルール
- 指示以外のコメントは使用しない
- 1つのUsecaseは1つの責任を持つ(Single Responsibility Principle)
- ドメインロジックはdomain層に委譲し、usecase層では調整・制御のみを行う
## ファイル構造ルール
### 基本構造
```
ユーザージャーニー/usecase/
├── {機能}/
├── {action}.go # 個別のusecase実装
└── {action}_test.go # テストファイル
```
## Usecase実装ルール
### 1. 基本構造パターン
```go
//go:generate mockgen -source=$GOFILE -package=mock -destination=../../../../test/mock/usecase/{domain_context}/$GOFILE
package usecase
// usecase構造体(小文字)- 実装
type actionUsecase struct {
entityRepository repository.Entity
dbConnection *db.DBConnection
// その他必要な依存関係
}
// Usecaseインターフェース(大文字)- 公開インターフェース
type ActionUsecase interface {
Execute(ctx context.Context, param1 Type1, param2 Type2) (*ActionDTO, error)
}
// ファクトリー関数 - DI実装
func NewActionUsecase(
entityRepository repository.Entity,
dbConnection *db.DBConnection) ActionUsecase {
return &actionUsecase{
entityRepository: entityRepository,
dbConnection: dbConnection,
}
}
// DTO定義
type ActionDTO struct {
ID int
UpdatedAt time.Time
// 必要なフィールド
}
```
### 2. 命名規則
- usecase構造体: `{action}Usecase`(小文字開始)
- Usecaseインターフェース: `{Action}Usecase`(大文字開始)
- ファクトリー関数: `New{Action}Usecase`
- Executeメソッド: 必ず`Execute`で統一
- DTO: `{Action}DTO`
...(エラー定義やテスト定義などなど)
## 依存関係ルール
### 許可される依存関係
- Domain層(model, repository interface)
- Infrastructure層(db, 外部サービス)
- 他のUsecase層(subusecaseの場合)
- 共通ライブラリ(apperror, util等)
### 禁止される依存関係
- Interface層(handler, router等)への直接依存
- Infrastructure層の具象実装への直接依存(DIで注入する)
※以降は全てのルールについて具体的に記載すると長くなってしまうため、簡単な説明に留めさせていただきます。
このようなルールファイルおよびPRD・DesignDocが人間とAIの間の共通言語として機能し、チームの規約に沿った成果物を安定して出力できるようになります。
次章以降では、PRDとDesignDocが存在する前提で、この「ルール」を活用して各工程をどう効率化したかを紹介していきます。
3. API定義書の作成・DB定義書の作成
私たちのチームでは、API定義書をOpenAPIで管理しています。
また、定義をcomponents/やpaths/のようにファイル分割して管理していました。
具体的には、次のようなファイル形式で管理しています。
/v1/resources/{resource_id}: get: summary: リソース詳細の取得 operationId: getResource parameters: - $ref: '../components/parameters/resource-id.yaml' responses: '200': $ref: '../components/responses/resource-success.yaml' '404': $ref: '../components/responses/not-found.yaml'
この構造がすでに整っていたおかげで、AI活用は思ったよりもスムーズでした。
命名規則とディレクトリ構造の簡単なルールを渡すだけで、AIがほぼ完璧に生成してくれます。
割とシンプルな構造なのでルールの整備もそれほど苦労はしなかったです。
エンドポイント5〜6個で半日〜1日かかっていた作業が、数十分〜1時間で終わるようになりました。
同様にDB定義書に関してもスキーマはある程度決まった記述になっていたので苦労はしなかったです。
4. ドメインモデリング
私たちのチームでは、ドメインモデリングを通じてシステムの持続可能性を高める取り組みを行っています。
詳細は過去の記事「持続可能なシステムを目指してプロダクトをリアーキテクトしました〜ドメインモデリング導入編〜」をご参照ください。
4-1. Before:ゼロからの作図と議論の往復で消耗
以前は、PRDやDesignDocをもとに、イベントストーミング図やドメインモデル図を人間がゼロからdraw.ioなどのツールで作図していました。
しかし、真っ白なキャンバスにエンティティや関係性を一つひとつ配置していく作業は、純粋な作図コストだけでなく、思考のノイズにもなっていました。「ここの関係線はどう引くべきか」「配置のバランスが悪い」といった些末な修正に時間を取られ、本質的な議論の時間が削がれてしまうのです。
結果として、議論の土台となる初版のモデル図を完成させるだけで1日〜数日を要し、そこからさらに修正を重ねるという重いプロセスになっていました。
4-2. After:ドキュメントとルールを渡すだけで設計図が生成される
この作図作業を効率化するため、ドメインモデリングのルールを明文化し、AIに渡すだけで図を生成する方式に切り替えました。
AIに渡すのは以下のドキュメントになります。
- PRD・DesignDoc
- ルール一式:
- DDDの基本原則(集約の境界、Aggregate Rootの役割など)
- ドメインモデルの記述フォーマット
- draw.ioでの図作成ルール(色、配置順序、命名規則など)
- ドメインモデリングの工程手順
プロンプト例:
このドキュメントとルールに基づいて、〇〇のビジネスユースケースにおいてイベントストーミング図とドメインモデル図を生成してください。
AIは、これらの情報からdraw.io形式(XML)の図を直接生成します。
もちろん、一発で完璧な図はできません。 しかし、「議論のスタートラインとなる質の高いたたき台」が一瞬で手に入ることの価値は計り知れません。
これまでは「ゼロから作図しながら議論する」ために膨大な時間を使っていましたが、今は「AIが出した80点の図をどう修正するか」というブラッシュアップの議論から即座に始められます。
結果として、1日〜数日かかっていた「議論ができる状態にするまでの時間」を大幅に圧縮できています。
実際の図を見てみます。
人間が作成したドメインモデル図
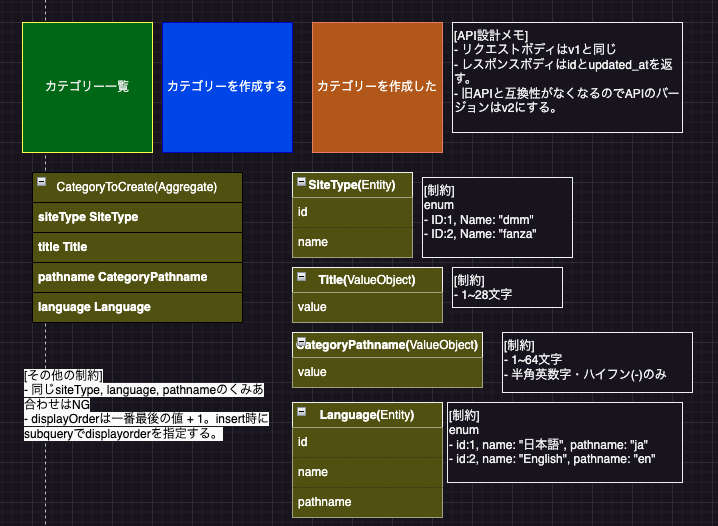
AIが生成したドメインモデル図

AIが生成する図は、集約の境界、エンティティと値オブジェクトの区別、リレーションシップの方向性など、基本的な構造はただしく反映されています。
ただし、ビジネスロジックの微妙なニュアンスや設計意図が不十分な場合もあります。だからこそ、レビューとブラッシュアップは不可欠です。
5. 実装
これまでの章で、API定義書やドメインモデルといった「設計の骨格」をAIの力で効率的に作り上げる方法を紹介しました。 ここからは実装フェーズです。この骨格に、私たちのチームが定めた「コーディング規約」という肉付けをすることで、どこまで実装を自動化できるのかをご紹介します。
5-1. レイヤーごとに「設計書」と「ルール」を渡す
私たちのチームでは、ドメイン駆動設計(DDD)に基づき、関心事をレイヤーごとに分離して実装を進めます。この実装プロセスの詳細やアーキテクチャ設計については、過去の記事「持続可能なシステムを目指してプロダクトをリアーキテクトしました〜 実践編 〜」で詳しく紹介していますので、こちらもぜひご参照ください。
AIに実装を依頼する際も、このレイヤー構造を意識させます。具体的にAIに渡すのは、常に以下の2種類です。
- 設計書:
- API定義書、DB定義書、ドメインモデル図、DesignDocなど、そのレイヤーの実装に必要な情報
- ルール:
- 各レイヤーの責務や実装パターンを定義した規約ファイル
1. ドメイン層の実装
ビジネスロジックの心臓部であるドメイン層では、「ドメインモデル図」と「ドメイン層のルール」を渡します。
プロンプト例:
このドメインモデル図とドメイン層のルールに基づき、モデル層の実装をお願いします。
ルールに記載されている規約(一部例):
- ファイル構造: 機能ごとにディレクトリを分け、
aggregate.go,entity.goのようにファイルを分割する。 - 集約(Aggregate): 操作は必ず集約のルートエンティティを通して行う。
- エラー処理: ビジネスルール違反は、
apperror.ErrTypeを用いて明確に定義する。
- ファイル構造: 機能ごとにディレクトリを分け、
AIはこれらの規約に従い、構造化されたコードを生成します。
- 生成されるコード例:
// resource.go - AIが生成したAggregate Rootの例 package model // Resource は何らかのビジネスリソースを表す集約ルートです。 type Resource struct { id int name string // ...その他のフィールド } // NewResource は新しいリソースを作成します。 func NewResource(name string, someBusinessRuleValue int) (*Resource, error) { if someBusinessRuleValue <= 0 { // ルールに基づき、ビジネスルール違反をエラーとして返す return nil, apperror.New(apperror.ErrTypeInvalidRequest, "ビジネスルールに関するエラーメッセージ") } return &Resource{ name: name, // ... }, nil }
2. Usecase層の実装
Usecase層では、「DesignDoc(特にシーケンス図)」、「ドメイン層コード」、「Usecase層のルール」を渡します。
ルールに関しては、2章で例示したものを利用しています。
プロンプト例:
設計図及びドメイン層のコードを元に〇〇のUsecase層の実装をお願いします。
生成されるコード例:
// create_resource.go - AIが生成したUsecaseの例 package usecase // CreateResourceUsecase はリソース作成Usecaseのインターフェースです。 type CreateResourceUsecase interface { Execute(ctx context.Context, input *CreateResourceInputDTO) (*CreateResourceOutputDTO, error) } type createResourceUsecase struct { resourceRepo domain.ResourceRepository dbConnection db.Connection } // Execute はUsecaseを実行します。 func (uc *createResourceUsecase) Execute(ctx context.Context, input *CreateResourceInputDTO) (*CreateResourceOutputDTO, error) { var createdResource *model.Resource // ルールに基づき、トランザクション内で処理を実行 if err := uc.dbConnection.WriterDB().Transaction(ctx, func(tx *gorm.DB) error { // ドメインモデルのコンストラクタを呼び出し resource, err := model.NewResource(input.Name, input.SomeValue) if err != nil { return err } // リポジトリ経由で永続化 if err := uc.resourceRepo.WithTx(tx).Create(ctx, resource); err != nil { return err } createdResource = resource return nil }); err != nil { return nil, err } return &CreateResourceOutputDTO{ID: createdResource.ID()}, nil }
3. インターフェース層・インフラ層・テストの実装について
長くなってしまうので割愛しますが、同様に、インターフェース層では「API定義書」、インフラ層では「DB定義書」をそれぞれのルールと共に渡すことで、必要なコードを生成できます。
もちろん、テストコードも例外ではありません。それぞれの層に「テストの規約」が整備されており、テストコードも自動で生成されます。
5-2. AI導入効果:実装の思考プロセスが変わった
このアプローチにより、実装の進め方が根本的に変わりました。
- Before: 各層の作法を思い出しながら、手作業でコードを記述。実装とテストに1日〜数日。
- After: AIに「設計書」と「ルール」を渡し、生成されたコードをレビュー・修正する。実装とテストが数時間〜1日で完了。
AIが定型的な実装を担ってくれるようになったことで、私たちは「この設計で本当に正しいのか」「ビジネスルールに抜け漏れはないか」といった、より本質的なレビューに集中できるようになりました。
6. 検証
実装が完了したら、次に来るのは検証フェーズです。 ここでいう検証とはAPIテストのことを指します。 私たちのチームでは、このAPIテストの領域でもAIを活用し、テスト資産(テストケース・テストスクリプト)の作成を自動化しています。
6-1. Before:テストケース作成と実行に数日
AI導入以前、私たちの検証プロセスは完全に手作業でした。
- テストケース作成: DesignDocやAPI定義書を読み解き、正常系・異常系のテスト項目を表形式で一つひとつ書き出す。
- テスト実行: Postmanを使い、作成したテストケースに従って手動でリクエストを送信し、レスポンスを目で確認する。
この方法は、テストケースの洗い出しと実行に数日単位の時間がかかることも珍しくなく、ヒューマンエラーのリスクも常にありました。
6-2. After:AIがAPI定義書からテスト資産を生成する
この時間のかかる検証作業を効率化するため、私たちはルールを定義し、それをAIに読み込ませることでテスト資産を自動生成するアプローチを取りました。
AIへの指示:
- API定義書(OpenAPI)
- DesignDoc
- 「テスト資産作成ルール」を定義したファイル
- プロンプト例:「このAPI定義書とルールに基づき、⚪︎⚪︎機能のテストケースを生成してください。」
ルールの要点:
- 段階的な生成: 全体を一度に作らず、正常系→異常系のようにセクションごとに生成・確認させる。
- 設定と実行の分離: APIごとのテスト設定は
configファイルに、テスト実行ロジックはspec.tsファイルに分離する。 - 既存パターンへの準拠: 新しいテストを追加する際は、必ず既存のテストファイルの構造や命名規則に従わせる。
この指示により、AIはまずテストケースとなるMarkdownを生成し、続いてその内容に基づき、次のようなPlaywrightのテストスクリプトを自動で生成します。
- 生成されるテストスクリプトの例 (
api-basic.spec.ts):
// tests/my-service/api-basic.spec.ts import { test } from '@playwright/test'; import { getItemApiTests } from '../config/my-service-api-tests'; import { runApiTest } from '../helpers/api-test-runner'; // ...(認証などの前処理) test.describe('📦 商品API', () => { // 設定ファイルからテストケース一覧を取得 const apiTests = getItemApiTests(); // ループで各テストを実行 for (const testConfig of apiTests) { test(testConfig.testName, async ({ request }) => { await runApiTest( request, baseURL, authHeaders, testConfig ); }); } });
6-3. AI導入効果:数日が数時間に
このアプローチにより、検証フェーズの作業は劇的に効率化されました。
- Before:
- テストケース作成と手動実行に数日
- After:
- AIによるテスト資産生成とレビュー、自動テスト実行で数時間
もちろん、AIが生成するテストも万能ではありません。特に複雑なシナリオでは人によるレビューと修正が不可欠です。 しかし、「API定義書があれば、テストコードの雛形が自動で出来上がる」という状態になったことで、検証作業の初動が圧倒的に速くなりました。
7. AI導入効果
各工程でのAI活用を積み重ねた結果、私たちのチームでは、これまで2週間かかっていたような規模の案件が、1週間程度で完了するようになりました。厳密な計測ではありませんが、新規開発案件においては工数が半分程度にまで短縮されたという強い手応えを感じています。
7-1. 開発速度の「好循環」への再投資
AIによって生み出された時間を、より多くの機能開発だけではなく、さらなる開発速度向上につながる活動へ再投資しています。 これにより、開発が速くなるほど、もっと速く開発できる体制が整っていくという「好循環」が生まれています。再投資先の例としては、以下のようなものが挙げられます。
技術的負債の返済: これまで後回しにされがちだったリファクタリングやライブラリのアップデートに時間を割けるようになりました。これによりシステムの健全性が高まり、将来の開発速度がさらに向上します。
新たなAI活用の検証: 本記事で紹介した以外にも、「コードの品質可視化をAIに任せる」といった次の実験に投資する余力が生まれました。これもまた、未来の効率化への投資です。
7-2. 客観的データから見る開発サイクルの高速化
こうした変化は、客観的なデータにも少しずつ表れています。
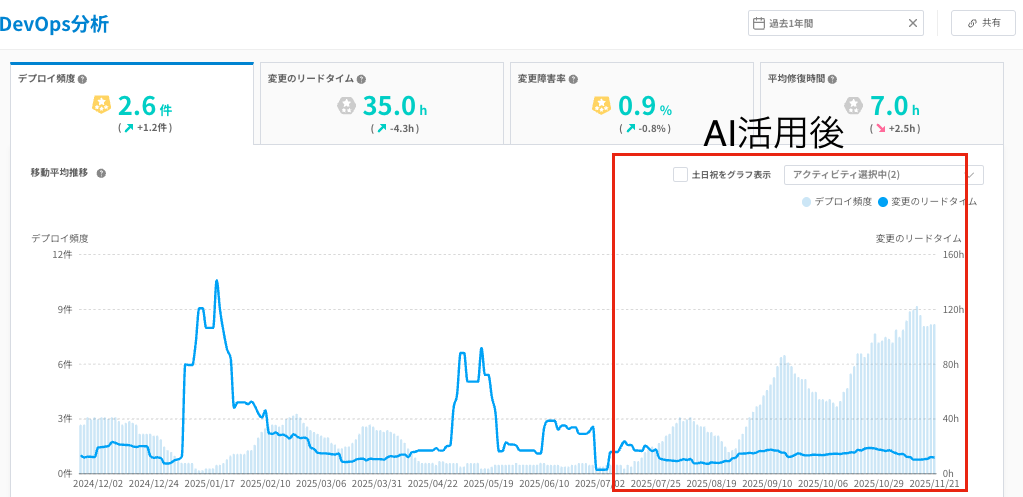 Findy Team+よりデプロイ頻度と変更リードタイム(期間: 2024年11月16日 - 2025年11月16日)
Findy Team+よりデプロイ頻度と変更リードタイム(期間: 2024年11月16日 - 2025年11月16日)
このグラフは、DevOps分析ツールFindy Team+が示す、私たちのリポジトリのデプロイ頻度です。
横軸が期間で棒グラフがデプロイの頻度、折れ線グラフが変更リードタイムを表しています。
なお、この期間においてチームの人数は変わっておらず、扱うタスクの粒度やプロジェクトの状況も過去と比較して大きな変化はありません。
それにも関わらず、AI活用を本格化させた7月以降、デプロイ数が明らかに増加しているのが分かります。
これに加えて重要なのが、リードタイム(変更のコミットからデプロイまでの時間)が悪化せず、安定して推移している点です。 通常、デプロイ頻度(=作業量)を急激に増やせば、レビュー待ちや手戻りが発生し、リードタイムは長期化・不安定化しやすいものです。
しかし、私たちのチームではデプロイ頻度が増加したにもかかわらず、リードタイムは以前と変わらず安定しています。
これは一見すると 「開発速度は変わっていない」 ように見えるかもしれません。しかし、AI導入による実装工数の大幅な短縮を考慮すると、短縮された時間の一部が増加したPRのレビュー時間や待ち時間によって相殺されていると考察しています(レビュー負荷の増大については次章で詳しく触れます)。
重要なのは、レビューというボトルネック要因が増大したにも関わらず、全体としてのリードタイムが悪化せず、 「チーム全体の処理能力(スループット)が向上した」 という点です。
特に9月以降にデプロイ数が加速しているのは、以下の要因が考えられます。
- より高性能なAIモデルの登場: この時期にリリースされたClaude 4.5 Sonnetにより、AIが生成する成果物の精度が向上しました。
- ルールの整備: 本記事で紹介してきたような各種ルールが整備され、AIへの指示がより的確に行えるようになったこと。
工数削減は、単なる効率化ではありません。チームの能力を拡張し、プロダクトと組織の成長を加速させるためのエンジンです。私たちのチームでは、AIがその役割を担い始めている兆候を観測できました。
8. 課題
AIの導入は、開発効率を向上させた一方で、新たな課題も見つかりました。
8-1. AIへの「一括指示」の難しさと「ルール」整備の重要性
当初、私たちは「PRDやDesignDocといった設計書だけを渡せば、AIがよしなに実装を完了してくれる」という理想を描いていましたが、これはうまくいきませんでした。各工程でAIに大きなタスクを一括で任せようとした結果、様々な問題に直面しました。
API/DB定義では、当初「この機能のAPIとDBを設計して」のように曖昧な指示を出した結果、命名規則はバラバラ、既存の設計資産も無視した、到底受け入れられない定義が生成されました。 → 3章で述べたように、ファイル分割の構造や命名規則といった「ルール」を整備し、それを明示的に渡すことで、初めて実用的な定義を生成できるようになりました。
ドメインモデリングでは、DesignDoc全体から一度に図を生成させようとすると、AIがドメインの境界を判断できず、実用性の低い図が生成されました。 → 「ビジネスユースケースごと」 に指示を分割し、ドメインモデルの基本的な概念をプロンプトに加えることで、初めて精度の高い図が得られました。
実装では、「この機能のコードを全部書いて」という一括指示では、レイヤー間の依存関係を無視した質の低いコードが生成されがちでした。 → 「レイヤーごと」 にアーキテクチャを意識して指示を分割することで、規約に準拠したコードが得られました。
テストでは、「このAPIのテストを全部作って」という一括指示では、テストケースの抜け漏れや、誤った内容のテストが頻発しました。 → 「テストケース生成」と「スクリプト生成」のように工程を分割することで、信頼性の高いテスト資産を構築できました。
このように、各工程でAIに適切なアウトプットをしてもらうためにはある程度の工夫が必要でした。人間がタスクを適切に分解し、従うべきルールを明確に定義して初めて、その能力を発揮します。一括でやらせようとせず、コツコツとレビューと改善を繰り返す地道な作業が不可欠です。
8-2. レビュー量の増加
AIがタスクを高速にこなすようになった直接的な結果として、レビューすべき成果物の量が増加しました。
実際、AIを本格的に活用する前の半年間ではPR数が1300件程度だったのに対し、直近の半年間では2000件程度と、およそ1.5倍に増えています。これに加えて設計書などのドキュメントレビューも増えており、体感的なレビュー時間は2倍近くになっています。
AIが単純作業を肩代わりしてくれた分、人間はより多くのレビューと意思決定を求められるようになりました。
CodeRabbitのようなAIレビューツールの活用も試験的に始めていますが、まだ人間の代替となるレベルではありません。 増え続けるレビュー負荷に対して、どのような体制やツール選定が最適なのかは、まさに現在進行形で模索している最中です。
8-3. 実装スキルから設計理解へのシフト
そして、「タスクの分解」と「レビュー量の増加」は、エンジニアに求められるスキルを変化させました。断片的な実装タスクをこなす能力以上に、PRDやDesignDocに書かれた仕様の背景や設計意図を読み解く力が、より重要になりました。
実際に、AI活用を始めた当初は失敗もありました。担当者が自分のタスク範囲の知識だけでAIに指示を出した結果、ドキュメント全体の意図とずれたコードが生成され、手戻りが発生したのです。
この経験から、私たちは設計プロセスそのものを変える必要性を感じました。
これまでは一部のメンバーが設計し、それを後からチームに共有していましたが、それでは共有を受ける側の理解がどうしても浅くなり、AIの生成物を正しく評価できなかったのです。
そこで現在は、AIを活用しつつ、ドキュメントをチーム全員でモブプログラミングのような形式で一緒に作り上げる方式を試しています。
AIを使えばドキュメントのたたき台はすぐに作れるため、全員が集まっても時間はかかりません。その場で議論し、合意形成しながら設計を作り上げることで、チーム全員が「なぜその設計になったのか」を深く理解した状態で実装に入れる状態を目指しています。
表面的な実装スキルだけでは、AIが生成した「一見動くが、仕様の意図を満たしていない」コードを見過ごしてしまいます。これからのエンジニアには、AIという強力な「実行者」をただしく導くための、より深いドキュメント読解力が求められます。
8-4. 現状の運用方針
これらの課題と向き合った結果、私たちのチームはAIとの分業というスタイルに落ち着きました。
- AIの役割: 人間によって分解された、具体的で単純なタスクを、ルールに従って超高速で実行する「実行者」。
- 人間の役割: ビジネス要求や設計意図を深く理解し、複雑な問題をAIが処理できる単純なタスク群に分解する。そして、AIの生成物をレビューし、最終的な意思決定を行う「設計者」であり「管理者」。
今のところ、私たちのチームではAIは銀の弾丸ではありませんでした。しかし、その特性を理解し、人間の役割を最適化することで、チーム全体の生産性を最大化できる。これが、私たちの現在の結論です。
9. おわりに
この記事では、私たちのチームがAIを開発プロセスに組み込んだ実例を、具体的な活用法から見えてきた課題、そして今後の展望まで含めてご紹介しました。
ここまで示したとおり、PRDやDesignDocといった精度の高いドキュメントが存在すれば、その後の開発工程の多くはAIによって効率化できます。
この成果は、AI導入以前から私たちのチームが培ってきた文化に支えられています。ドメイン駆動設計(DDD)の思想に基づき、人間が理解しやすいドキュメントを整備し、厳密なコーディング規約を運用する。そうしたチーム開発の基本を地道に積み重ねてきたことが、期せずしてAIが能力を発揮しやすい環境を構築していました。
AIの特性を理解し、明確な「仕様」を共通言語として対話を重ねることで、AIは人間の思考を加速させる強力なパートナーとなり得ます。
この記事が、皆さんのチームでのAI活用の取り組みや検討の際に、少しでも参考になれば幸いです。
宣伝
プラットフォーム開発本部では専門性の高いメンバーと協力しながら、時には他部署のエンジニアやマネージャーとも連携し、自らのアイデアをプロダクトへ落とし込み、ユーザー価値を高めていける環境です。 この記事で紹介したような取り組みは部全体のごく一部にすぎず、部署によってはさらに高度な技術的挑戦や大規模な改善活動に取り組んでいるチームも存在します。
チームとプロダクトの成長を共に支え、次のステージをつくっていく一員になりませんか? 少しでも興味を持っていただけた方は、ぜひ下記の採用ページをご覧ください。