

- はじめに
- レポート
- ラスベガスどうだった?
- さいごに
はじめに
みなさんこんにちは。動画配信開発部 動画配信インフラグループ SRE チームの飯島貴政(いいじまたかまさ)です。
今回は新卒 3 年目である私と、新卒 2 年目になった山本暉能(やまもとあきよし)さんがラスベガスで開催された Google Cloud Next 25 に参加してきたので、その内容をお伝えします。
本記事では、前半を飯島、後半を山本が担当します。
記事の最後には会場の様子がわかる動画も載せていますので、ぜひご覧ください!
レポート
Opening Keynote: The new way to cloud
今回のGoogle Cloud Next 25では、AI エージェントおよび Gemini が大きくフィーチャーされている印象を受けました。
- Gemini / Imagen 3 / Chirp / Lyria / Veo2
- いままで単体で動作してた AI エージェントが連携して動作するようになった
- Agent Development が公開され、OSS フレームワークとして開発が可能になりました。
- つまり Google Gemini の Agent を利用して、Google Cloud 上で自分の AI エージェントを開発できるようになりました。
- AI Agent とパートナーサービスの連携
- Google Gemini の AI エージェントは、Google Cloud 上で動作するだけでなく、パートナーサービスとも連携して動作できるようになりました。
- 例えば、Google Gemini の AI エージェントを利用して、Salesforce や SAP などのビジネスアプリケーションと連携できるようになりました。
個人的に Keynote で感動したデモは、Web 通販サイトの問い合わせに対して、AI エージェントが自動で応答するデモでした。 このデモでは、AI エージェントが Web 通販サイトにリアルタイムのビデオで問い合わせし、AI がリアルタイムで応答できるようになりました。例えば、「このお花に合う肥料はどれ?」という問い合わせに対して、AI エージェントが「素敵なペチュニアですね!それに合う肥料はこちらです!」といったもはや人間と同じようなカスタマーサービスとして応答できたところです。 (会場も拍手喝采でした!)
Maximize your cloud ROI- A practical approach to efficiency and optimization.
Google Cloud や他のクラウドサービスを利用する際、コストの最適化は非常に重要なテーマです。
私自身も DMM に入社してチームにジョインしてから、DMM TV をはじめとする Google Kubernetes Engine (GKE) を利用したサービスの運用に携わってきました。しかし、GKE のコスト最適化は非常に難しいと感じています。
GKE Standard クラスタを利用している場合、GKE のコストは主に以下の2つの要素から構成されています。
クラウドサービスを用いる際にはネットワークトラフィックのコストについてもすごく重要なのですが、今回はGKEのコストにフォーカスしてお話しします。
1. GKE Standard クラスタの管理コスト
GKE Standard クラスタの管理コストとは GKE を使うことで必ず発生するコストです。
完全に自動化されたクラスタ ライフサイクル管理、Pod とクラスタの自動スケーリング、費用の可視化、インフラストラクチャ費用の自動最適化が含まれます。 クラスタあたり 1 時間ごとに $0.10 の料金が発生します。 https://cloud.google.com/kubernetes-engine/pricing?hl=ja
2. GKE Standard クラスタのノードプールのコスト
GKE の実態は Google Compute Engine の VM (VM = 仮想マシン) です。
GKE Standard クラスタのノードプールは Google Compute Engine の VM の集合体です。
GKE の pod が利用するリソースは増えれば増えるほど、必要となる CPU やメモリの量も増えます。その結果、VM の数も増加します。VM の数が増えればコストにも直結します。
ただし、システムの冗長性や可用性を考慮すると、VM の数を単純に減らせば良いというわけではありません。
ただ従来であればコストを削減したいといってもたくさんの要因 (例えば DMM TV であれば、舞台配信といった大型イベントの有無や昼夜リソースの使用状況差) が絡み合っており、一辺倒には実現できませんでした。
このブレイクアウトセッションでは新しく発表された 以下の2つの機能を利用することで、 GKE のコスト最適化がより簡単に着手できるようになったように感じました。
- Google Cloud Assist
- Cloud Hub
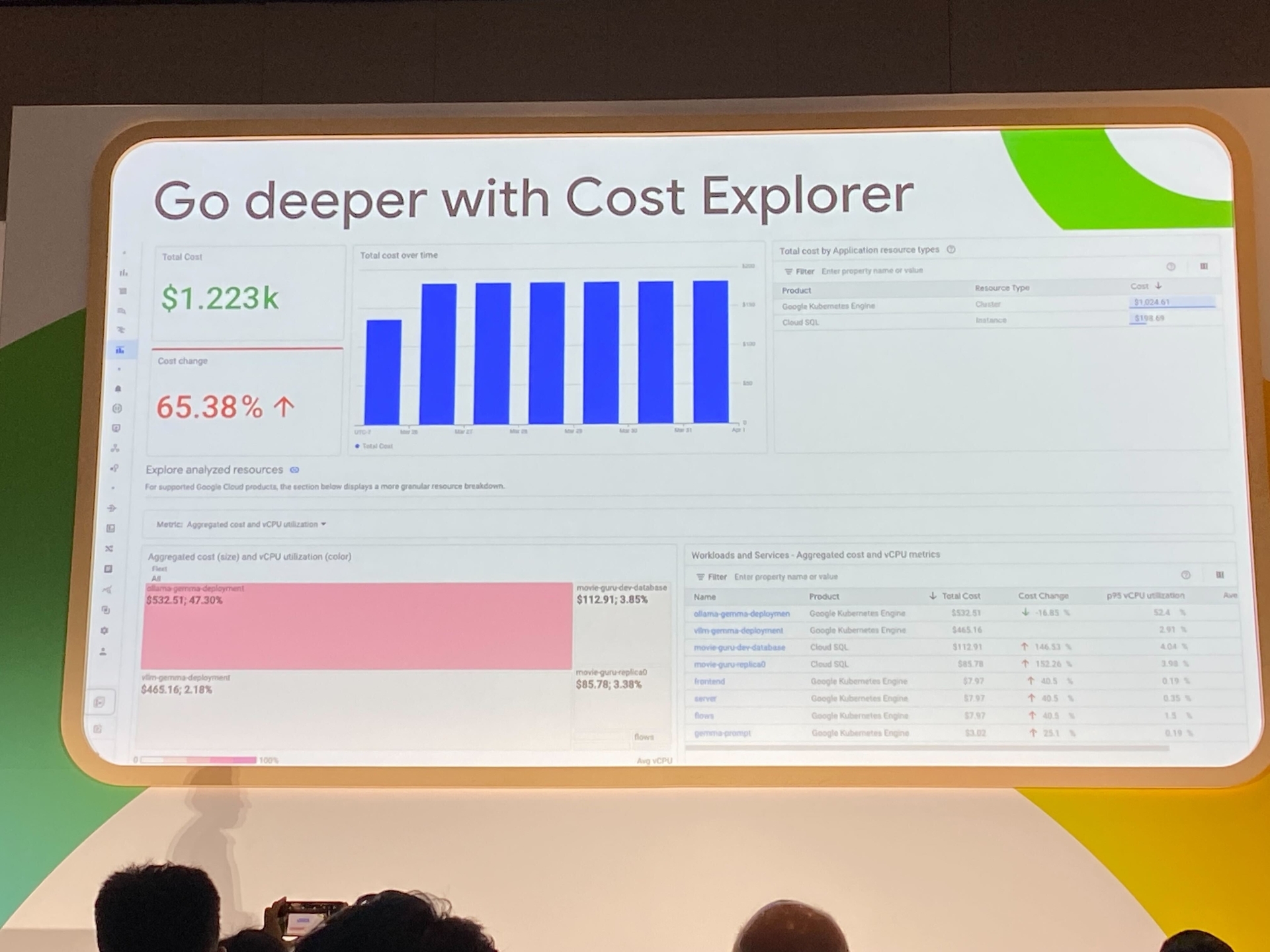 これらによって今までも確認できたハイレベル(ノード=VMの料金やストレージの料金)のコストの情報がよりわかりやすくグラフになって確認できるようになりました。
これまで従来調査コスト(時間)が非常に高かった Workload レベルでのコストの情報も手軽に確認できるようになりました!
これらによって今までも確認できたハイレベル(ノード=VMの料金やストレージの料金)のコストの情報がよりわかりやすくグラフになって確認できるようになりました。
これまで従来調査コスト(時間)が非常に高かった Workload レベルでのコストの情報も手軽に確認できるようになりました!
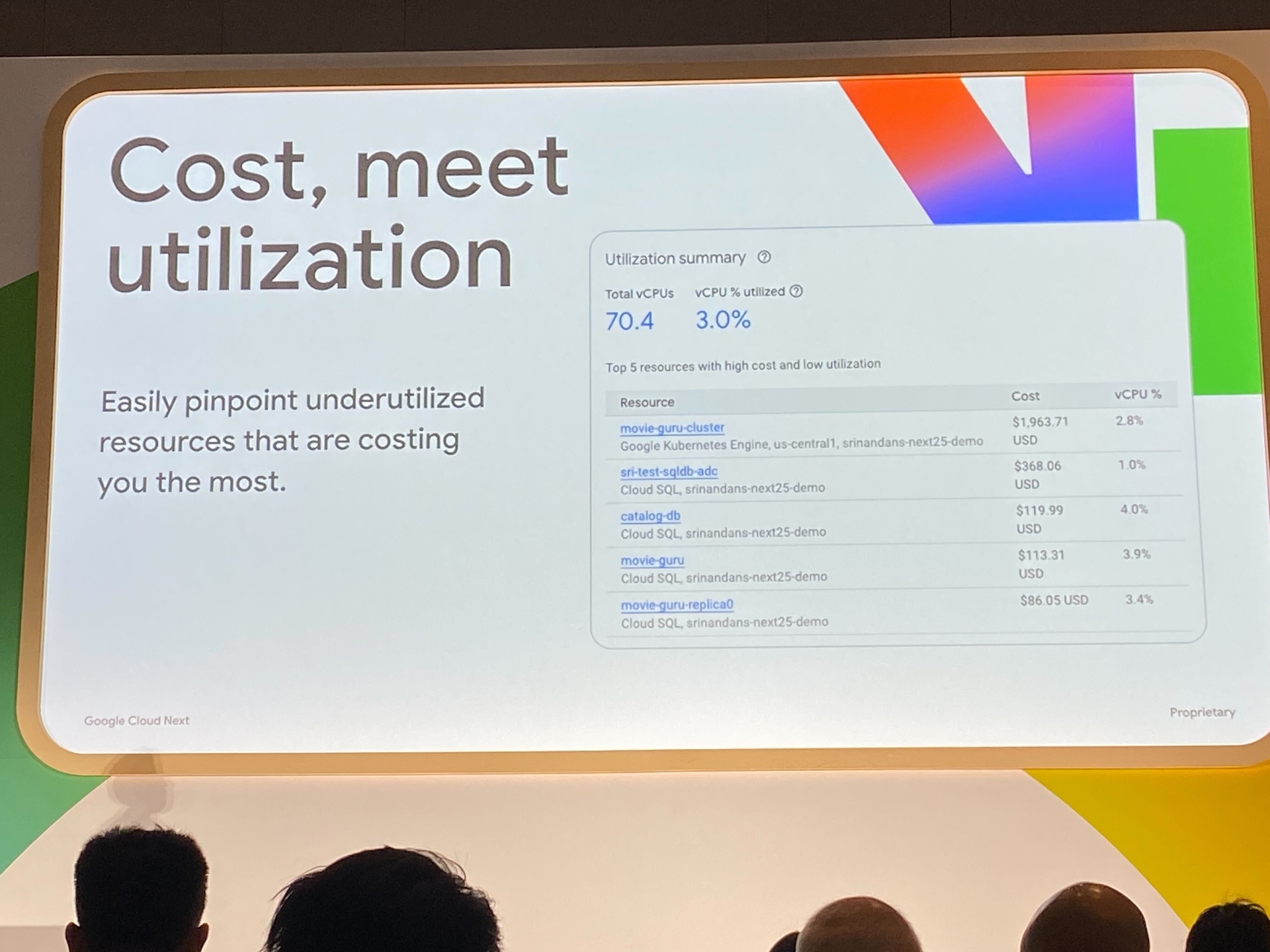 (今までは vCPU と Cost の関係は手動で計算するか外部のツールを使う必要があり、とても大変な作業でした)
(今までは vCPU と Cost の関係は手動で計算するか外部のツールを使う必要があり、とても大変な作業でした)
このセッションでは MLB (メジャーリーグベースボール) の事例を交えながら、GKE のコスト最適化のためにどのようにこれらの機能を活用しているかを紹介していました。
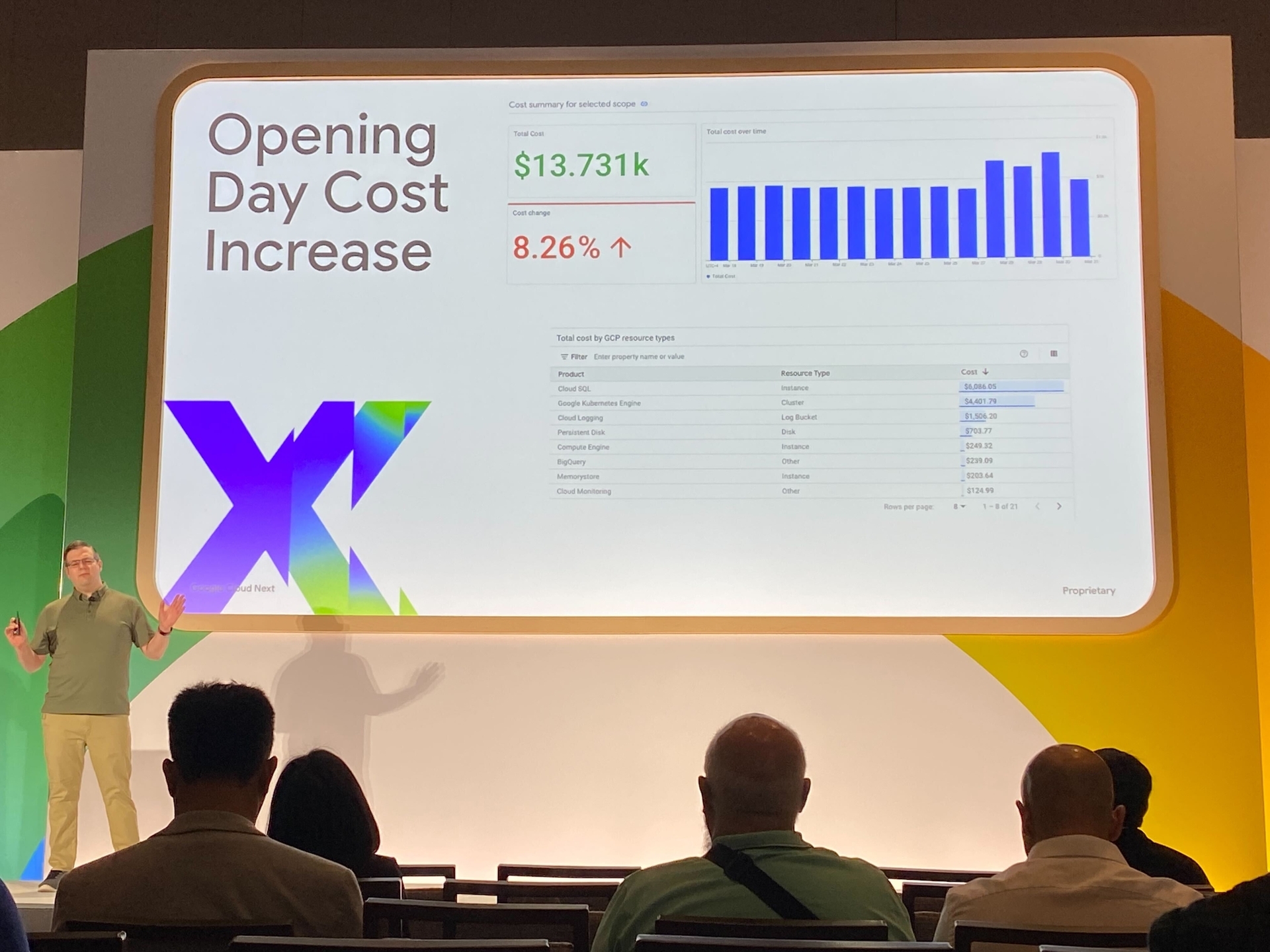
コストに対する視覚的な情報が整理されてより理解しやすくなりました! いままで FinOps Hub で見られているものとは別の情報が見られるようになったので、Cloud Hub もぜひ試してみてください!
Observability(可観測性)について
可観測性に関して以下の2つのセッションを見てきました!
- Master OpenTelemetry- Scale and streamline observability pipelines
- Future of observability- Top five predictions from the experts.
近年、 OpenTelemetry (OTel) に統一していく流れがあります。
OpenTelemetry は、アプリケーションのパフォーマンスを監視するためのオープンソースのフレームワークであり、Google Cloud では Observability の重要な要素として位置付けられています。

このセッションでは OpenTelemetry と Google Cloud の統合について、以下のようなトピックが紹介されました。
Gemini Cloud Assist との統合によって OpenTelemetry のデータを簡単に収集し、分析できるようになりました。
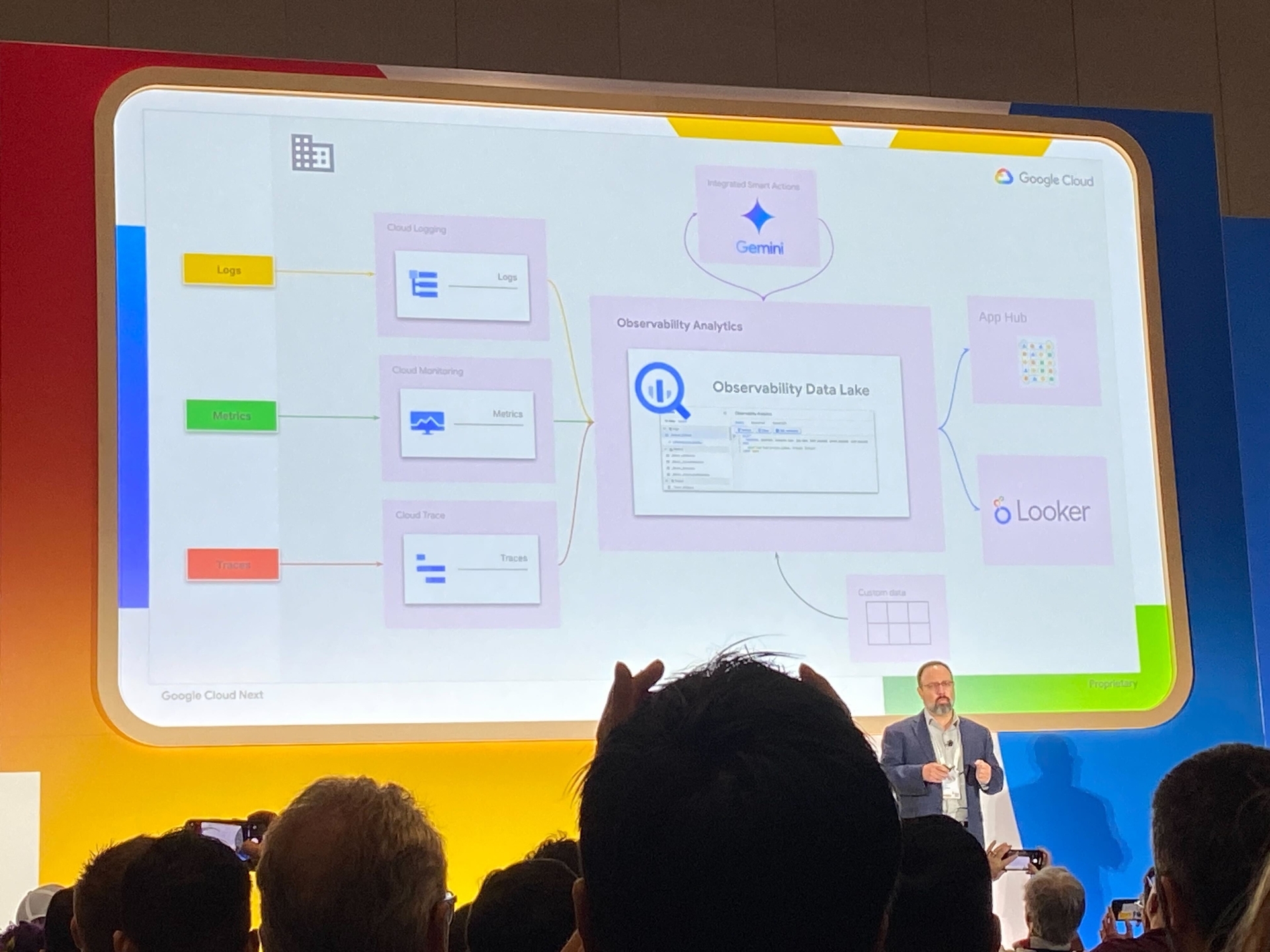
OpenTelemetry が、メトリクス、ログ、トレースの計測、収集を今後さらに Google Cloud やその他のクラウドプロバイダも含めてサポートしていくことが期待されています。 また BigQuery や Looker、Gemini Assist などの Google Cloud のサービスと統合することで、データの分析や可視化が容易になります。コスト最適化のところでも触れましたが、GKE の Pod のリソース使用量の推移や傾向を掴むのは従来であれば推測や経験則に頼る部分が多いものでした。これからは大量のメトリクスを有効に活用して Gemini と連携することで、より正確な予測ができるのではないかと感じました。
今後、実際にチームに展開してみて、どのように活用できるかを考えていきたいと思います。
Developer Keynote 「You Can Just Build Things」
Google Cloud Next の Developer Keynote では、AI を活用した次世代のアプリケーション開発に焦点が当てられました。
このキーノートでは、Agent Development Kit、Agent Engine、Google Agentspace が紹介されました。

生成 AI による開発者の生産性向上や業務効率化は、DMM の開発組織としても関心のある領域で、今後の展開に注目しています。
こちらの記事で、最新のDMMの生成AIに関する取り組みについても紹介していますので、ぜひご覧ください。
developersblog.dmm.com developersblog.dmm.com
GKE turns 10 and looks to the future of Kubernetes

「GKE turns 10 and looks to the future of Kubernetes」では、GKE の 10 周年を振り返りつつ、Kubernetes の将来に向けた展望が語られました。
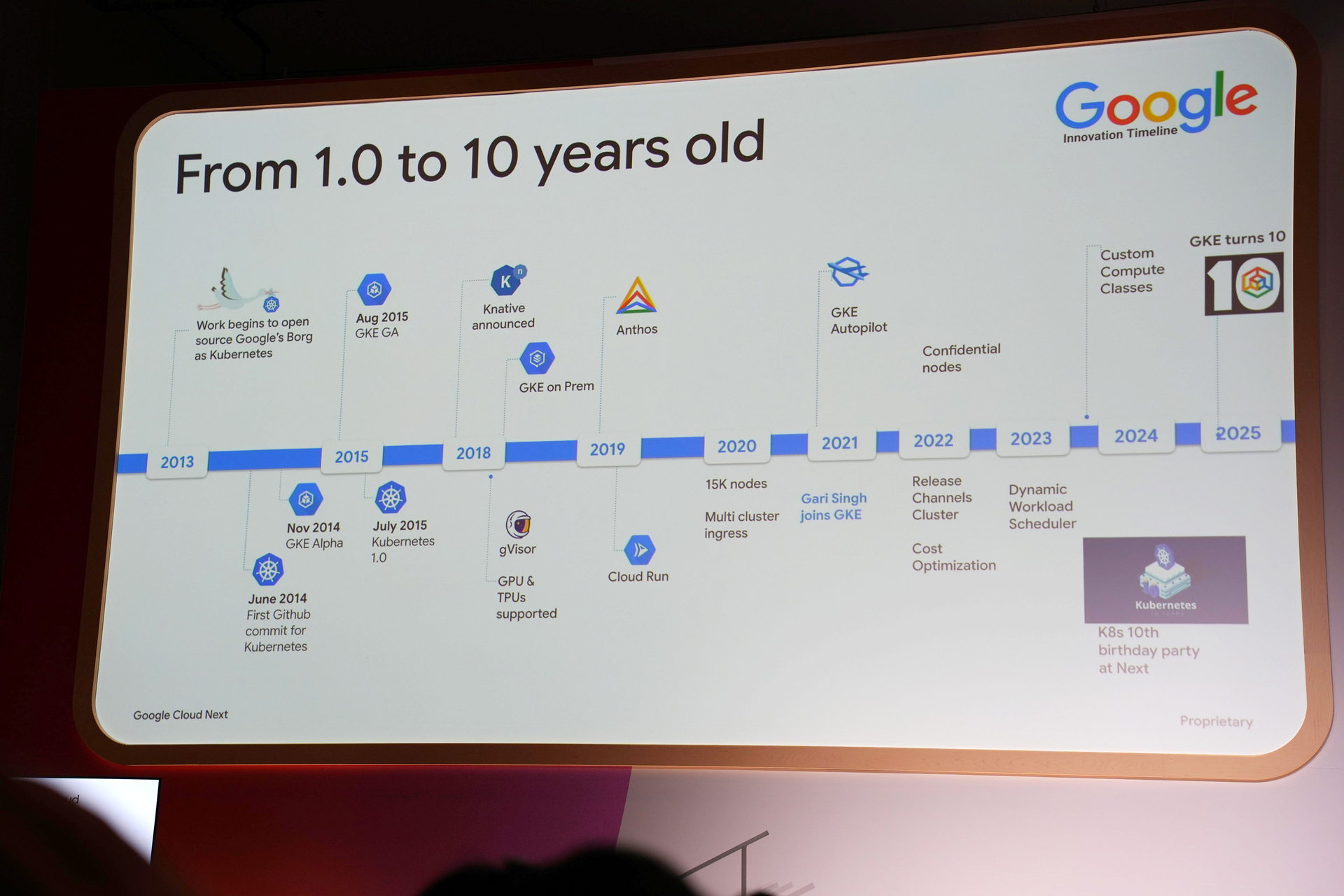
Google は、毎週 40 億を超える新しいコンテナを起動するコンテナプラットフォームの中核であり、主要な Google 製品で GKE の利用が拡大していることを紹介していました。
また、Kubernetes の起源である Borg からの進化、そして 2015 年の GKE の登場からのイノベーションの歴史が紹介されました。
GKE は、ユーザーが意識する必要のないセキュリティや信頼性に重点を置いており、大規模なワークロードに対応するためのスケーラビリティの進化、例えば 65,000 ノードや 50,000 の TPU チップのサポートなどが紹介されています。
この成果は、次に紹介するさまざまな機能強化が合わさる形で達成されます。
GKEの最近のアップデート
一般的なKubernetesクラスターにおいて、クラスタの状態管理をするためのコンポーネントに分散型 Key-Value ストアであるオープンソースの etcd を利用しています。
Google はこの etcd から、新しくより堅牢な Spanner をベースとした Key-Value ストアへの切り替えに取り組んでいます。
この変更により、より大規模な GKE クラスタをサポートできるようになるだけでなく、クラスタの起動やアップグレードのようなオペレーションの改善につながります。
Spanner ベースのストレージに etcd API を実装することで後方互換性を確保し、新しいテクノロジーの導入でコアの Kubernetes に変更を加えなくてもよいようにしています:
参考記事
また、GKE のオートスケーリング機能の進化も紹介され、特に GKE 1.32 の Autopilot では、Pod の 1Pod → 10Pod のスケールアップがわずか 8 秒で完了するデモが披露されました。
これは、Pod の高速なスケジューリング、最適化された水平 Pod オートスケーラー(HPA)、そしてコンテナ最適化コンピューティングといった技術によるものです。
特に気になったアップデート
今回紹介された中でも特に興味深かった、3 点について紹介します。

In Place Pod Resize は、ポッドを再起動することなく、CPU やメモリなどのリソースサイズを動的に変更できる機能です。これにより、例えば Java アプリケーションのように起動時に多くの CPU を必要とし、通常時はそれほど必要としないワークロードにおいて、リソースの過剰なプロビジョニングを防ぎ、効率的なリソース利用が可能になります。Vertical Pod Autoscaler (VPA) などの自動スケーリング機能が、より実用的なものになると期待されています。
こちらの機能は、GKE Autopilot 1.33 以降で Alpha/Beta として利用可能になる見込みです。
特に、レガシーアプリケーションのクラウドリフトフェーズにおけるインフラ最適化の文脈において威力を発揮する機能になるのではないかと考えています。
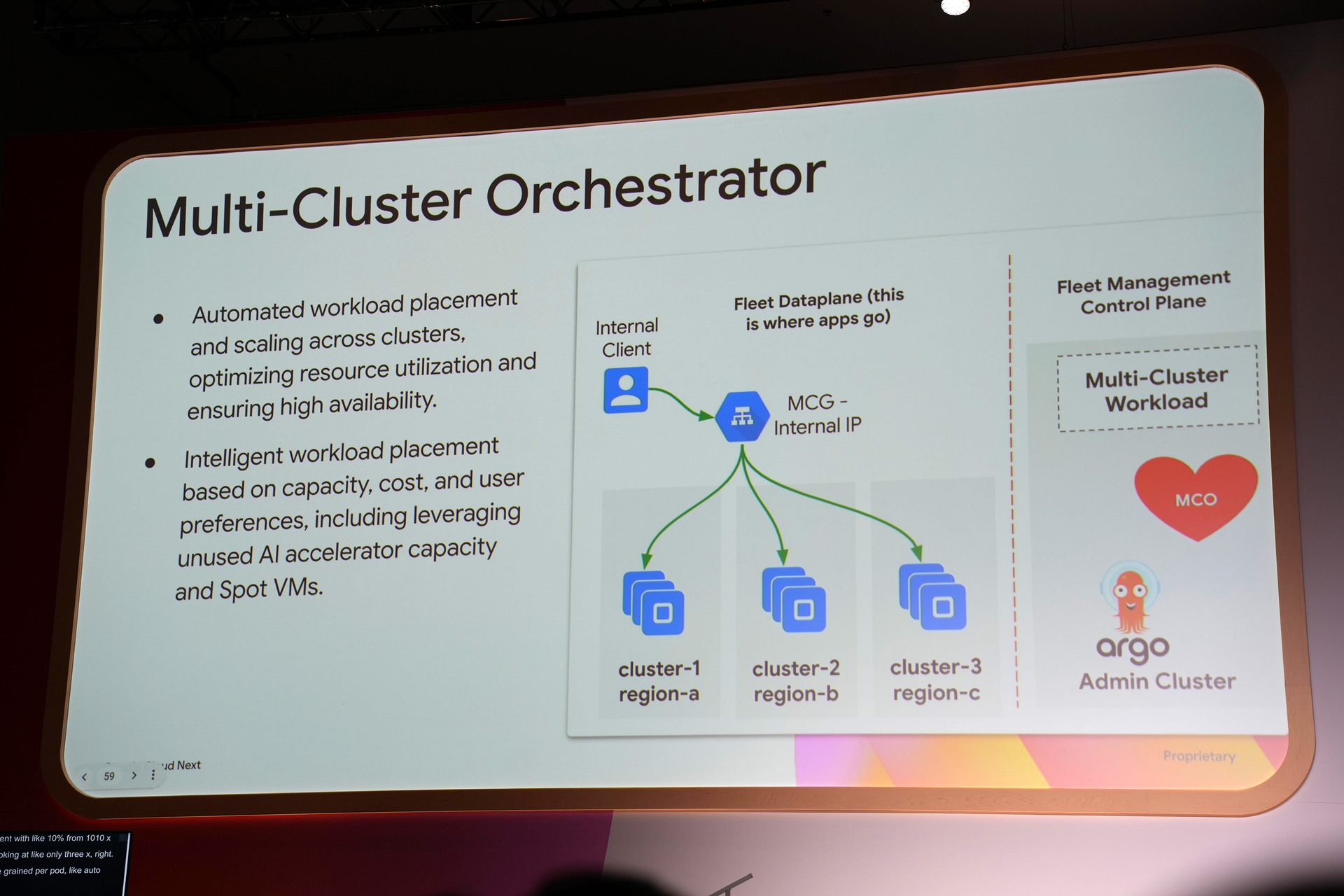
Multi-Cluster Orchestrator は、複数の Kubernetes クラスタにわたるワークロードのデプロイ、スケーリング、管理を統合的に行うための機能です。これは、KubeCon EU 2025 で Google、Microsoft、AWS などが共同で発表された標準仕様と、その GKE 実装になります。リージョンを跨いだ高可用性の実現や、容量の柔軟な拡張、特定のリージョンへのトラフィックの優先付けなどが可能になります。
DMM Platform では、EKS/GKE のマルチクラスタ環境を構築しているため、今後の展開が楽しみです。
Composite Resources は、関連する複数のクラウドリソース(例えば、アプリケーションのポッドとそれに対応するデータベースインスタンス)を、単一の Kubernetes カスタムリソース定義(CRD)として管理できるようにする仕組みです。これにより、アプリケーションのデプロイや管理をよりシンプルにし、インフラストラクチャのプロビジョニングからアプリケーションの実行までを Kubernetes の枠組みの中で一貫して行うことが可能になります。異なるクラウドプロバイダーのリソースも統合的に管理できる可能性についても触れられていました。
What’s new in Cloud Run

「What’s new in Cloud Run」では、Cloud Run に関する最新情報が解説されました。
Cloud Run チームの方々に加え、実際に Cloud Run を活用している会社の方も登壇され、具体的なユースケースも交えながらの紹介でした。ここでは、特に印象に残ったアップデート内容を中心にご紹介します。
開発者向けアップデート
まず、開発者体験を向上させるためのアップデートがいくつか発表されました。
特に大きな変更として、従来の Cloud Functions が Cloud Run Functions として Cloud Run に統合された点が挙げられます。
これにより、関数もコンテナやソースコードと同様に Cloud Run で一元的に管理できるようになります。
注目すべき改善点は、インスタンスごとの同時実行性です。 従来の FaaS と異なり、デフォルトで複数のリクエストやイベントを同時に処理できるため、リソース効率が向上し、レイテンシやコストの削減が期待できるとのことです。
従来不可能だった GCS (Google Cloud Storage) のマウント が可能になったり、Google Code Assist による AI コーディング支援が組み込まれたりと、機能面でも強化されています。
このほか、ロードバランサーなしで Identity-Aware Proxy が利用可能になり、内部向けサービスの認証が容易になりました。また、Gemini Cloud Assist と連携してリソース最適化やトラブルシューティングの支援を受けられるようになるなど、細かな改善も進められていました。

次に、AI 推論やバックグラウンドタスクといった、新しいタイプのワークロードへの対応も強化されています。
注目すべきは、AI 推論ワークロード向けの Cloud Run GPU が、ついに正式に一般提供開始となったことです。
高速なコールドスタート(約 5 秒)や、CPU と同様の従量課金制、ゼロからの高速スケーリングといった特徴を持っています。
NVIDIA L4 をはじめとした GPU を利用して、カスタムモデルのデプロイからリアルタイム LLM 推論、画像生成まで、幅広い AI タスクをサーバーレスで実行できるようになります。
バッチ推論やモデルのファインチューニング向けに、Cloud Run ジョブで GPU を利用する機能 も Preview として発表されました。

もう一つの新しい発表が、Cloud Run Worker Pools です。
これはリクエスト駆動ではなく、常時実行型のバックグラウンドタスク専用 の新しいリソースタイプで、キュー処理やデータストリーミングなど、継続的な処理が必要なワークロードに適しています。Worker Pools のユースケースとしては Kafka コンシューマーや Pub/Sub Pull、GitHub Actions のセルフホストランナー基盤 として利用されることも想定されています。CI/CD 環境をより柔軟かつ効率的に構築できる可能性があり、個人的にこの点は非常に興味深く、実際に使ってみたいと思いました。
エンタープライズ向けアップデート
エンタープライズ利用を見据えた機能強化も進んでおり、実行中のコンテナの脅威を検出する Container Threat Detection が Cloud Run でも利用可能になっています。
他にも、ロードバランサーとの組み合わせによるマルチリージョンでの高可用性 (HA) 構成 の実現についてもあらためて言及がありました。
また、Cloud Run がコンテナベースで任意のフレームワークを実行でき、ストリーミング応答や Gen AI API との連携、GPU 利用も可能なことから、AI エージェントを実行するためのプラットフォーム としても優れている点がアピールされました。

ラスベガスどうだった?
ご飯が大きい & おいしい
アメリカと言えば『肉!ピザ!ハンバーガー!どれもビッグサイズ!』というイメージがありましたが、まさにその通りで期待を裏切らないボリュームでした。
物価の高さもさることながら、やはり量が多い分、全体的に値段も高く感じられることが多かったです。
ただ、例えば旅行中に食べたあるハンバーガーは、サイズも値段も日本のものと大きくは変わらず、手頃で満足できるものでした。

無料トラム
ラスベガスでは、ホテル間(特に同じ系列など)を結ぶ無料トラムが運行されていることがあります。
例えば、私たちが宿泊したホテルからCloud Nextの会場があるホテルへも、このトラムを使って移動できました。
トラムは無料で運行間隔も短く、非常に便利でした。
高架線を走っているので、下を歩くこともできますし、部屋の窓からトラムが行き交う様子を見ることもできました!


一つの都市に世界が詰まっている感じがしました
私は(飯島)アメリカにいくのは初めてでしたが、ラスベガスの街並みはアメリカというよりは世界の縮図のようなイメージを受けました

エッフェル塔や自由の女神、ギリシャ調の建物もあり、観光をすると半日ではかなり物足りなさを感じるくらいには楽しめました。
特に日本では現状触れることのないカジノの文化や、 Google Cloud Next の参加費に含まれている The Killers のライブ等で街全体として訪問した者を楽しませよう! という気概を感じて非常によかったです。
初日ラスベガス到着〜Keynote会場までを動画にしてみました!
以下の動画は、初日にラスベガスに到着してから Keynote 会場までの様子をまとめたものです。
ラスベガス自体はおそらく検索で出てくるような観光地の情報が多いと思いますが、私たちが実際に Google Cloud Next 25 に参加した際の様子をお伝えできればと思い、動画にしてみました!
この動画で雰囲気が伝われば幸いです。
さいごに
オンラインによるセッション視聴も可能な一方で、参加者との交流は現地参加することでしかできません。また、国内イベントでは味わえない雰囲気や、他の参加者とのネットワーキングも貴重な体験でした。学びにとどまらず、業務に活用できそうなプロダクトの情報を得たり、その改善アイデアも浮かんだので、まずは概念実証を試してみようと思っています。
さて、ここまで新卒2年目、3年目の私たちが、 Google Cloud Next 25 に参加した様子をお伝えしてきました。
けど..海外のカンファレンス参加費や渡航費は高額だし...! となりますよね!
私たちはカンファレンス参加支援制度と呼ばれる福利厚生制度を用いて参加しました。
この制度は、カンファレンス参加費用および渡航費用を会社が負担してくれる制度です。
Google Cloud の他にも AWS re:Invent や KubeCon など、様々なカンファレンスに参加する機会を得られるかもしれません!

そんな DMM ですが、現在 2026 年新卒の採用活動中です。
DMM で働くことに興味がある方はぜひエントリーしてみてください。
インターンも募集していますので、実際に DMM での就労を体験してみたい!という皆様はぜひご応募ください!
dmm-corp.com