

はじめに
こんにちは!データサイエンスグループの西潟とデータアプリケーショングループの河西です。
私達のグループでは、DMM.comの数百万を超えるコンテンツを情報検索や機械学習を使ってユーザーにパーソナライズして届けるために、検索・レコメンド改善を行っています。
現在弊社では全文検索エンジンを Solr から Elasticsearch への移行を検討しています。
スムーズに移行できるように Elastic社には移行当初から多大なご支援をいただいておりますが、その一環で 2024年7月2日 ~ 3日にアメリカ・サンフランシスコにあるElastic本社に招待いただき、今後のロードマップや現在のハイライトをヒアリングさせていただいたので 今回は、DMM Developers Blogにて共有させていただきます。


Elastic Solution Briefing参加の背景
改めて参加の背景を簡単にお伝えします。弊社ではこれまで全文検索エンジン、サジェストエンジンに Apache Solr を用いて DMM の各サービスにこれを提供してきました。 今後の検索エンジンの運用コストやトレンドなどを鑑み、マネージドな検索エンジンを検討したところ、Elastic Cloud が候補に上がり、既にサジェストエンジンは Elastic Cloud に移行が完了しています。よろしければその際の記事も御覧ください。(https://developersblog.dmm.com/entry/2024/06/12/120000)
現在は全文検索エンジンを移行するために Elastic Cloud の検証を進めています。まずは現状の Solr で提供している全ての機能を Elastic Cloud に移植するだけがファーストステップとなりますが、これが完了したらスムーズに Hybrid Search や LTR など高度な relevancy 改善施策を打てるように調査を進めていたところ、Elastic社からサーチ系の内容で Elastic社の PdM の方など直接講義する機会をいただけるとのご提案をいただき、この度 Elastic社のサンフランシスコオフィスでの 2 日間の Briefing に参加することになりました。
また、Elastic Solution Briefing自体は今回で2回目の開催となり、弊社以外にも、Elasticのサービスを利用している会社様を対象に、複数社が参加されました。
今回のブリーフィングでは、以下のトピックについて、説明いただきました
- Elastic overview
- Search highlights & roadmap
- GenAI with Elastic
- Learn to Rank
- Vector DB
- Serverless
以降で、西潟・河西それぞれセッション内容及び感想についてお伝えします。
セッションの紹介(西潟)
西潟からは主に relevancy に関連するセッションの内容についてお伝えします。
Hybrid Search
文字列マッチングと AND や OR などの演算子を用いて検索する旧来の検索モデルのことを lexical search と言ったりします。現在も多くの検索サービスがこの lexical search で実装されており、DMM も lexical search がベースとなった検索サービスを提供しています。一方で昨今、と言ってもかなり以前からですが、vector search と呼ばれる検索モデルが検索サービスによく用いられるようになり、我々がよく使うテキストで検索できる動画配信サービスや音楽配信サービスでも vector search が多く用いられるようになっています。vector search はクエリとドキュメントをベクトルで表現し検索できるようにすることで、lexical search で課題であったクエリがドキュメントに必ず出現しなくとも意味的に似ていればヒットさせられるようになりました。これを巨大な文書集合に対して高速にできるようになったことが近年の特徴かと思います。
Elasticsearch では 2019 年にリリースされた 7.13 から vector search がサポートされています。8.9 からは lexical search と vector search の両方の結果をうまくマージするための機能が実装され、これを Hybrid Search と呼んでいます。
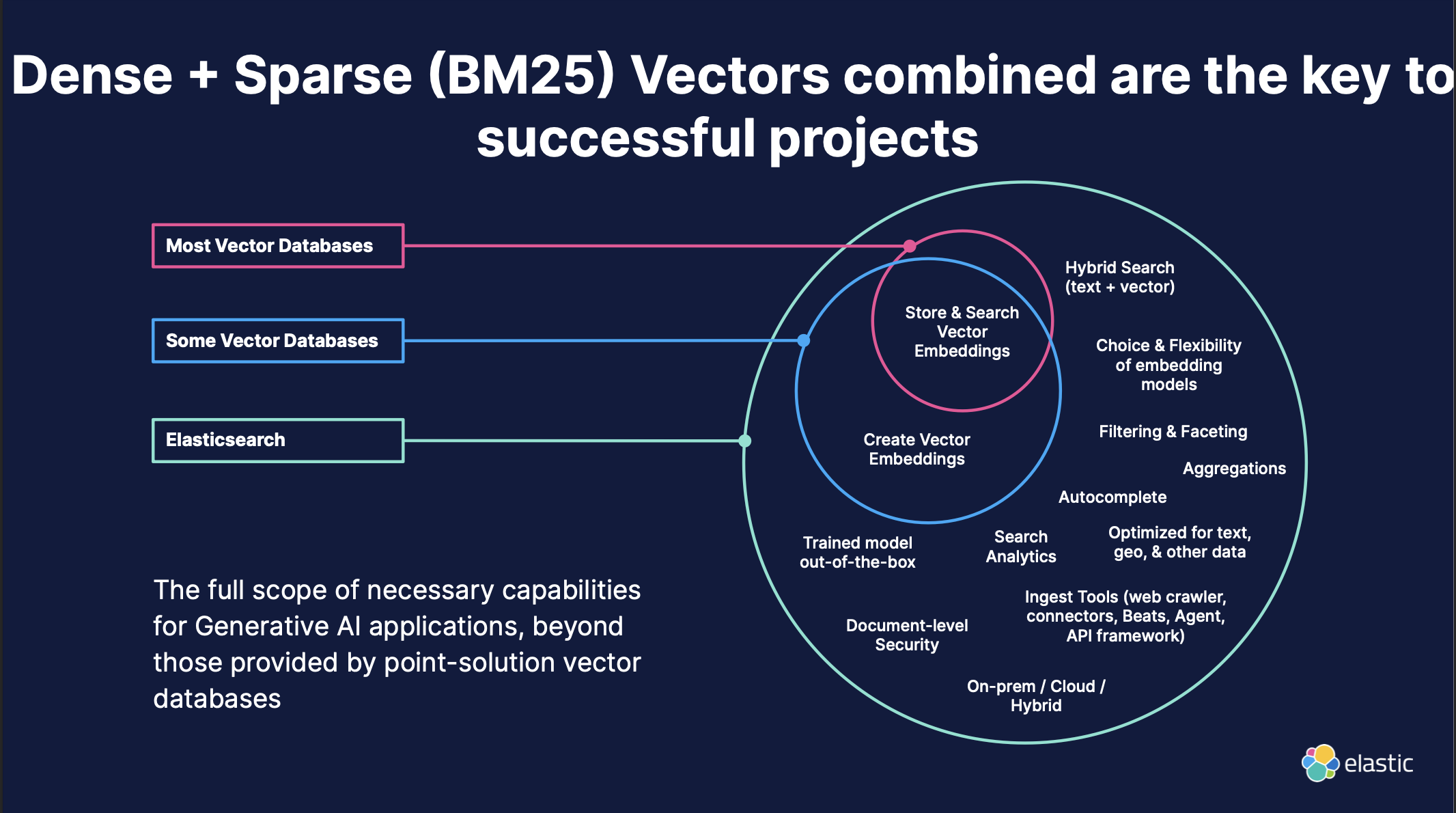
よく利用される vector search のエンジンに Pinecone や Vertex AI Vector Search があります。Elasticsearch では特に 2023 年以降に実装されたデータの量子化技術によって、ベクトルフィールドが圧縮できるようになり、先に挙げた vector search エンジンよりも非常に高速に動作することを本 Briefing で改めて主張されていました。そして Elasticsearch は lexical search とのハイブリッドが可能という点でこれらの vector search エンジンと大きく異なります。DMM では解釈性の観点から、引き続きユーザーのクエリに対して忠実に文字列マッチングした結果を返すべきだと考えていますし、価格やジャンルでの忠実な絞り込みも必須であると考えています。これらの機能を実現した上で、更に高度な relevancy 改善に取り組もうと思った時、ただの vector search エンジンでは要件を満たすことは難しいと考えています。もちろんハイブリッド検索機能を持った検索エンジンは Elasticsearch だけではないですが、Lucene からの取り込みの早さ、量子化による高速化などは Elasticsearch の有利な点だと考えていますし、今回の Briefing でもその点は非常に強く主張されていたため、改めて Elasticsearch を選定できていることに安心感を覚えました。
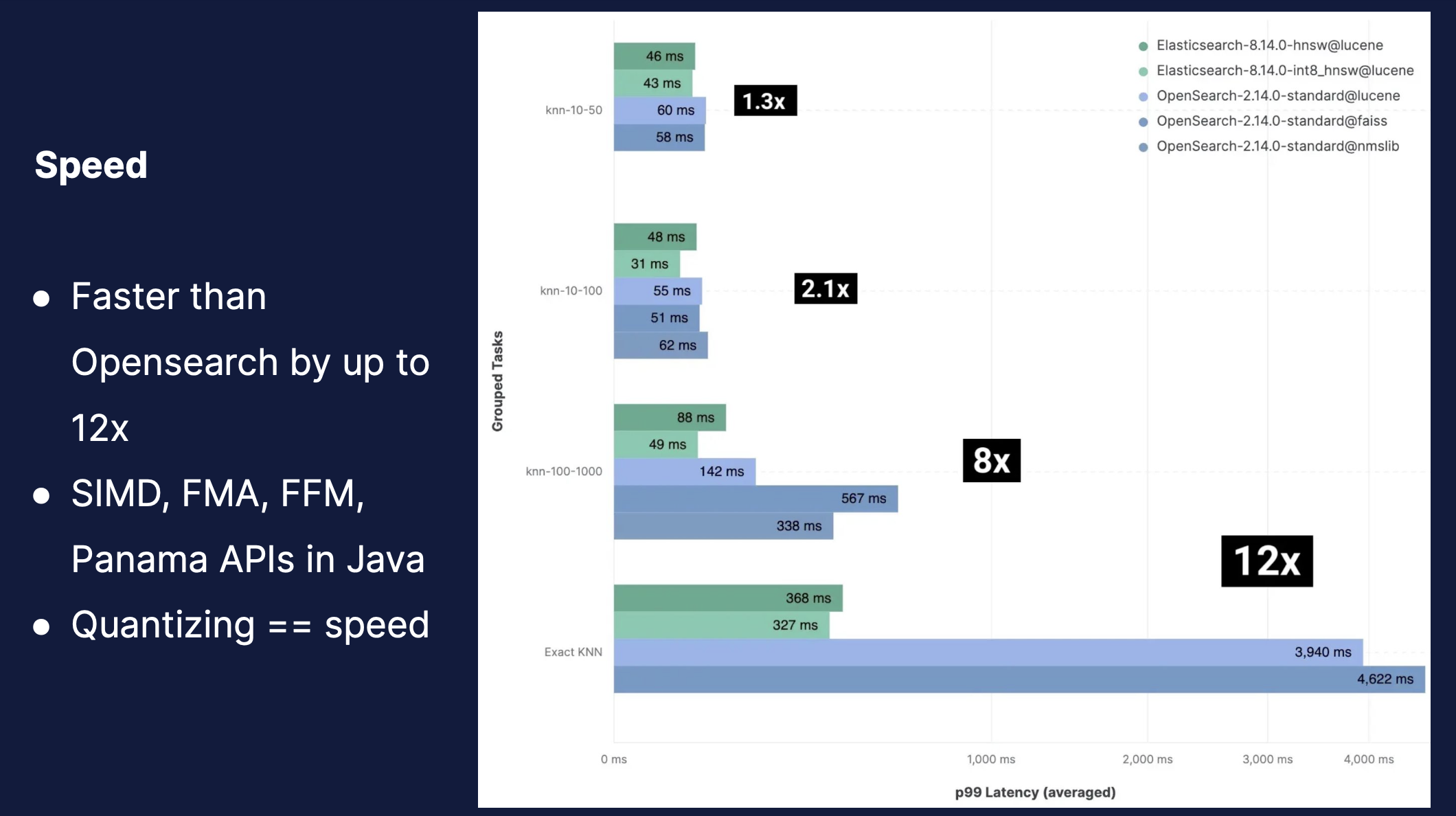
Briefing では今後のロードマップも話していただき、詳細は省きますが、新しいドキュメントの類似度計算や更に高速に探索するアルゴリズムの話も出ました。 今後 DMM では更に検索改善を加速させていきたいと考えているため、こちらのスピード感や高めていきたいと考えている分野の機能と Elastic社との足並みが揃っていそうだと感じました。
Learn to Rank
LTR(Learn to rank) のセッションもあったため、共有します。LTR はドキュメントの並びを学習する手法で、分類や回帰といった一般的な機械学習の予測モデルとは異なり、ドキュメント間の相対的な重みや順位そのものを予測することが特徴です。LTR は 10 年ほど前から盛んに議論されてきた分野かと思いますが、DMM ではまだ積極的に取り組めておらず、Elasticsearch に移行できたらまずは積極的に取り組みたい機能の1つではあります。
Elasticsearch では 8.14 から LTR が native support されるようになりました。これまでプラグインのバージョンを合わせる必要があったなど、この煩雑さがなくなったため、今後 DMM としても LTR に取り組みやすい状況ができてきたと思います。
DMM では現在検索エンジンへのパラメータをユーザー個別に最適化して検索する層と、そのレスポンス数100件程度を user embedding と content embedding でリランクする層の2層の検索を行っています。 現在の検索トレンドはここに中間層を1つ設け、ここで LTR を用いていることが多いと思います。セッション中でも3層の multi stage ranking について言及がありました。1層目は 100k 以上のドキュメントに対しては高速に検索が可能な BM25 や近似最近傍探索を用い、そこから得られる 1k から 10k くらいのドキュメントに対し LTR のモデルを噛ませ、最後の 100 ほどのドキュメントに対して重いモデルを適用する例が挙げられていました。
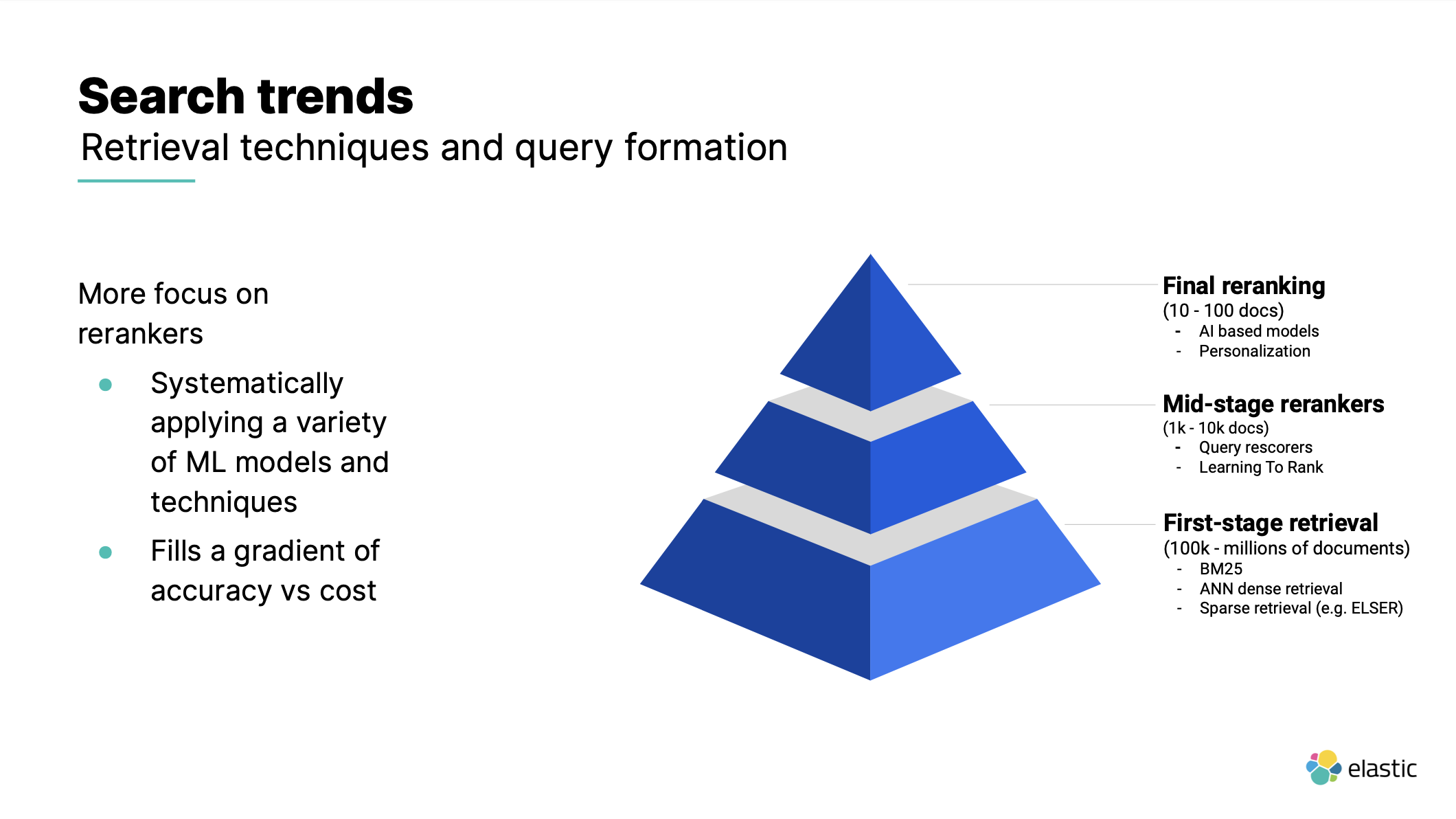
DMM ではこの2層目の reranker を検索エンジン内部で行うほうが良いのか、外部で行うのが良いのかこれから検証していきたいと思っています。レイテンシだけを考えれば 10k のレスポンスの通信を一旦外の reranker と行うことはコストでしかないと考えられますが、扱えるモデルや今後の柔軟性を考えた時 2 層目の reranker を外出しする意義がどれくらいありそうなのか検証の余地があると考えています。
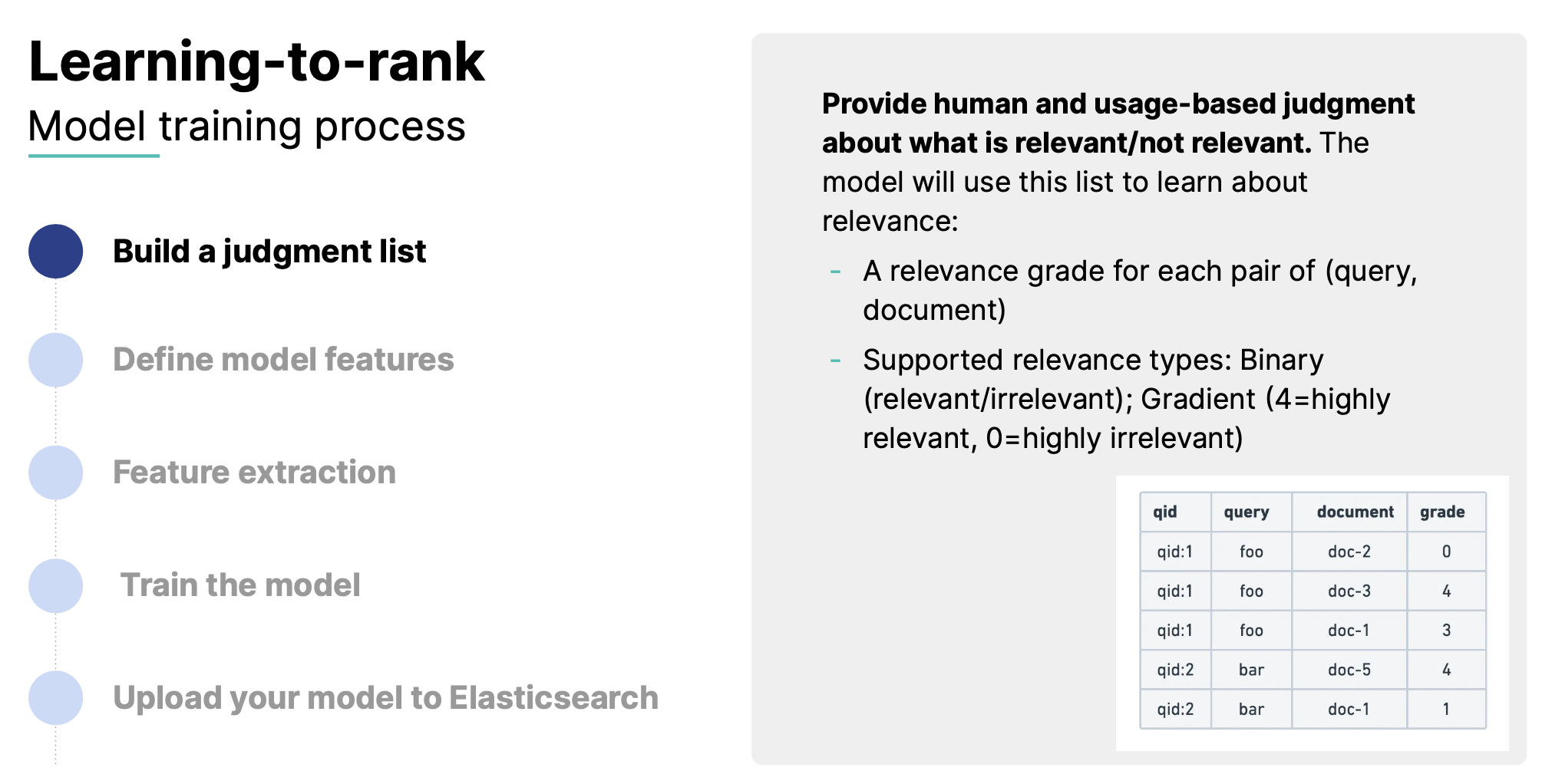
LTR では、順位を学習するためにクエリと検索結果がペアになった検索ログを用います。例えば、bar というクエリで検索した時に doc1~doc10 が返り、doc1 と doc5 がクリックされて、doc5は購入されたとかです。順位を学習するためのデータの作り方はいくつかありますが、理想はクエリに対するドキュメントの重み付きリストを作れたら最高です。ナイーブに検索ログからこれを作ろうと思うと、クリックされたドキュメントは分かりますが、クリックされなかったドキュメントを重みが低いドキュメントとして扱うべきかどうかは議論の余地がありそうです。またクリックされなかったドキュメントの並びをどうすれば良いかも判断が難しいことも想像できます。
Elasticsearch ではこのようなログのことを judgement list と呼んでおり、judgement list の作成を自動化することに力を入れているとセッションで述べられていました。雑談でしたが、今後は judgement list を LLM を使ってどう自動化するかは参加者とも議論になっていました。本当に意味のあるクリックや興味がないドキュメントが LLM によって判断され judgement list を作れるなら、我々は Elasticsearch を使うだけで勝手に良いランキングが作られる世界観になりそうです。少なくとも今後はこのような世界観が見えてきたので DMM では積極的に LTR のチューニングにチャレンジしていきたいと考えています。
全体の雰囲気や感想
総勢 20 名ほどが Elastic社の会議室の中に入り、以上のようなセッションを Elastic社の Matt さんや Yaru さんはじめ、様々な方に講義していただきました。まだ Elasticsearch を触り始めて間もない我々からすると、サーチ系の機能や今後のロードマップなど、これまでをうまく Wrap up してくれたような内容になっており、とても充実した時間を過ごせたと思います。
既に Elasticsearch を十分に活用されている方にとっては既知の情報が多かったかもしれませんが、それでもサンフランシスコのオフィスで Elastic社の PdM の方と直接議論しながら理解を深められることはなかなかありません。また参加人数が少ないからこそ、参加者どうしで議論しあいながら進行できていたこともとても貴重な経験だったと思います。僅か2日間ではありましたが、Elastic社のメンバーになった気持ちで学べる機会を与えていただいた Elastic社に心から感謝いたします。
まとめ
Elastic社のサンフランシスコオフィスで開催された Elastic Solution Briefing の内容について、主に Hybrid Search と Learning to rank 周りについてお伝えしました。どちらも非常にスピード感を持った機能開発がされていることが分かり、競合他社と比べても十分に競争力があるプロダクトに仕上がっていることが理解できる内容だったと思います。LTR については現状はまだいくつかの limitation がありますが、今後はそれが徐々に解消される話もあり LTR を使った柔軟な開発を進められそうです。
データサイエンスグループでは lexical search からの早い脱却と、高度な機械学習プロダクトに取り組むため、Hybrid Search と Learing to rank に対して積極的に投資していきたいと考えています。
余談
Elasticsearch Japan 代表の山賀さんの計らいで、サンフランシスコで有名な巨大なカニをご馳走になり、メジャーリーグ観戦までさせていただきました。どちらも参加者の親睦を深め、今回の Briefing を記憶に定着させる本当に良い経験でした。Elasticsearch Japan の方々の温かいホスピタリティを感じられ、隅から隅まで充実した2日間でした。
セッションの紹介(河西)
河西からはObservabilityやServerlessといった基盤に関連するセッションの内容をお伝えします。
Elastic overview
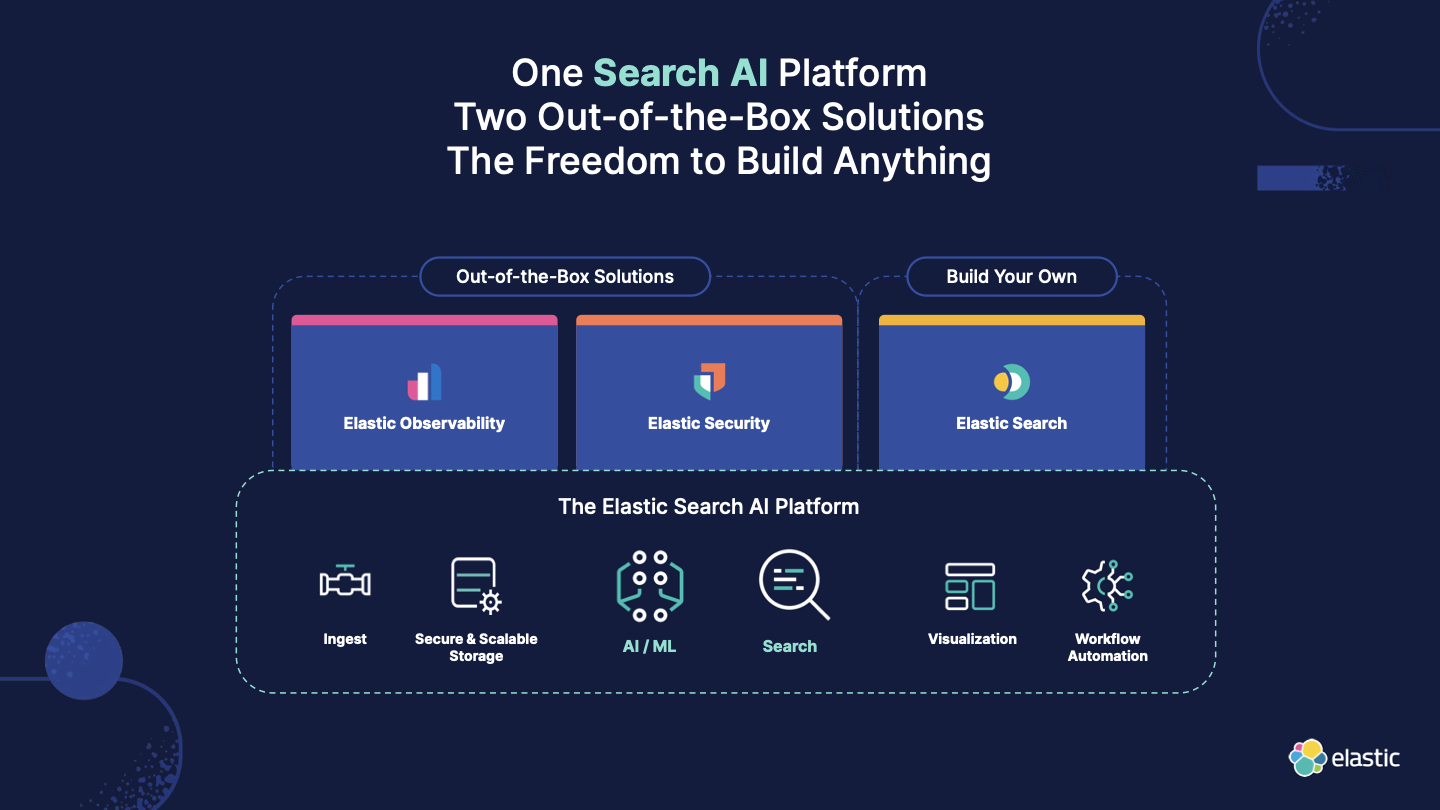
Elasticの全体概要と今後のロードマップについて、紹介いただきました。
The Search AI Company として、Search・Observability・Securityと全ての方面に対して、Search AI Platformとして強化していく方針とのことで、vector searchなどと組み合わせて利用できるのはElastic社のみだと強調されていました。
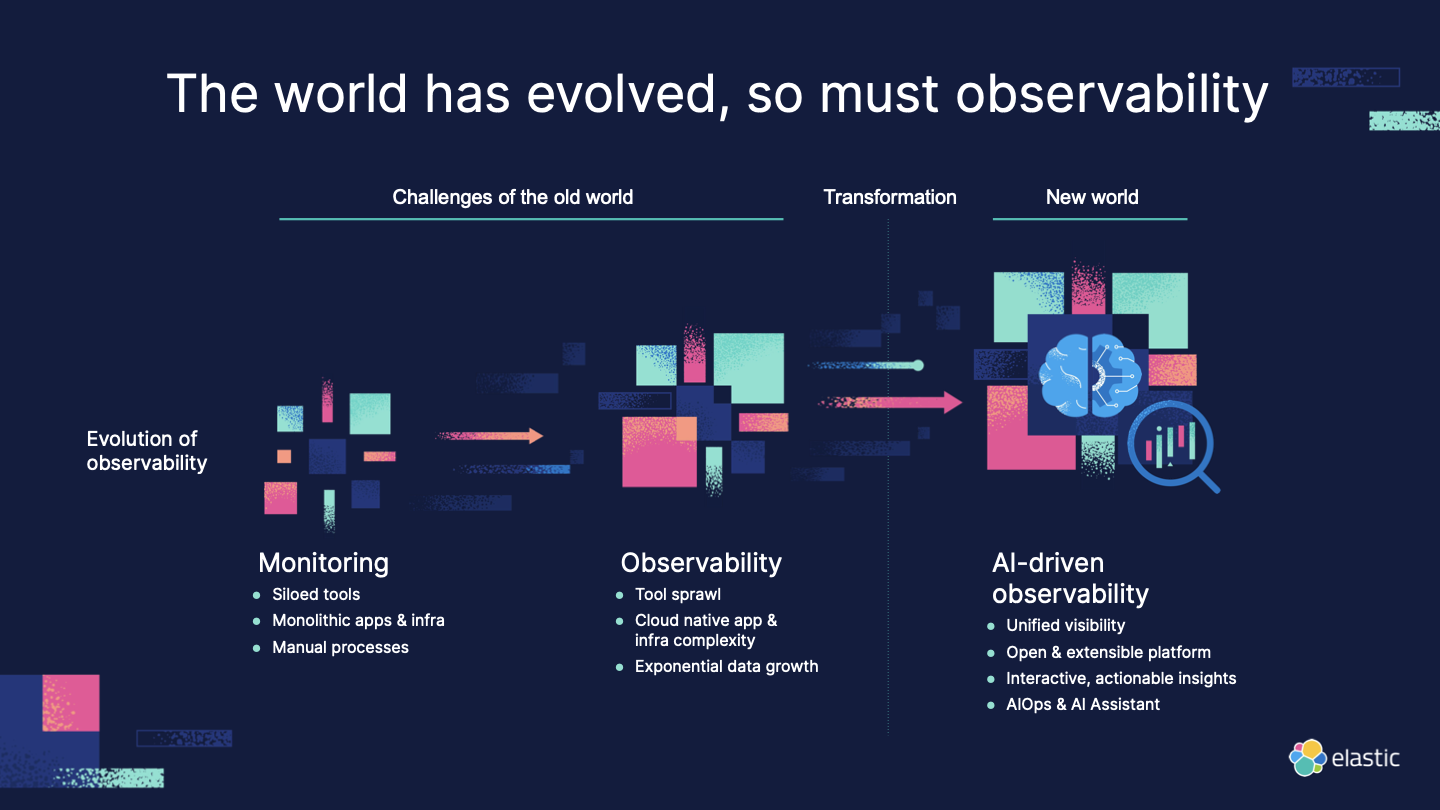
Observability
中でも個人的に興味深かったのは、Observabilityの部分です。以下のように、旧来のツールやアプリケーションを駆使した手法からAI-drivenな手法に変わっていくとのことです。
AI-drivenとは、今までのLogs、Traces、Metricsといった3本柱に加えて、RUM(Real User Monitoring)やKPIなど様々なデータを駆使して、AIアシスタント(LLMを利用したチャット)から分析ができるようになるようです。
実際のDemoでは、Logベースのアラートからチャット形式で会話をして、ビジネスインパクトまでを分析する様子を見せていただきました。
弊チームでもObservability Toolsとして、Datadogを利用しています。調べたところ同様なソリューションがありました。したがって、今後このようなLLMを活用したObservabilityは当たり前の世界になっていくと思いますし、LLMを活用するためにもデータの整備を勧めていくべきだと感じました。

感想
今回のブリーフィングのメインがLTRやVectorDBといったトピックのため、ObservabilityやSecurityといったトピックはこちらのOverviewでしか扱われなかったところが、個人的には少し残念ではありますが、Elastic社が考える今後のロードマップを知ることができて良かったと思っています。
Elastic Cloud Serverless Overview
Elastic Cloud Serverlessのセッションでは、概要や将来的な対応予定について説明を頂きました。
Elastic Cloud Serverlessとは、Deploymentsの管理無しに各プロジェクトを利用できるサービスで、管理コストの削減やオートスケーリングの対応等、個人的に気になっている機能です。

Launch Phase
Elastic Cloud Serverlessは現在Technical previewとなっており、一部のAWSリージョンのみ利用できる状態となっています。
スケジュールまでは言及されていませんでしたが、パブリッククラウドに関しては、将来的にGoogle Cloudにも対応され、機能面では、TrafficFilterや、Cross-Project(Observability、Elasticsearchの相互通信)にも対応していくようです。
Architecture
Serverlessのアーキテクチャは以下の様になっており、従来のデータTierはなく、Indexing TierやSearch Tierといったよりシンプルな構成になっているようです。これを実現しているのが、Search Ai Lakeで、Serverlessはこの仕組みを利用しているとのことでした。
実際どの程度のパフォーマンスがあり、Latencyが発生するかなどは、ユースケースによりますが、
- Boost Window
- Search Power
- Data Retention
といった指標の組み合わせによって変化するため、このあたりは様々な条件で負荷テストしてみるのも良さそうです。

AutoScaling
AutoScaleについては、以下にあるようなメトリクスやリソースから、判別しています。
これ以外にもMLやKibanaにも対応しているようです。
index
- Utilization
- Queue size
- Response time
- Queued time
search
- node数・サイズ
ただし、注意点として、現状は、indexingやsearchのパフォーマンスを維持するため、ゼロスケールはせず、最小のnodeが常に起動する仕組みになっています。
したがって、後述するコスト増にもつながっていくと考えています。
ブリーフィングでは、このあたりの今後の対応については、言及はありませんでしたが、改善されることを期待しています。
コスト
気になるコストですが、VCU(Virtual Compute Unit)という単位で、計算が行われ、インスタンスタイプやCPU、RAM、Diskから決定されます。
基本的には現状のプランより確実に高くなると言っていました。
ですが、コストダウンに向けて検討されているようで、GAまでには更に最適化されている可能性はあると思います。
感想
個人的に気になっていたサービスだったため、概要やロードマップを聞けて良かったです。
また、ディスカッションで議論されていた事項として、例えば月末月初などの限られた期間しか使わないシステムにおいては、工数をかけずに構築したい(かつ利用する時だけシステムを立ち上げたい)という要望があり、そういったケースではServerlessを利用したいという需要が多いようです。
したがって、将来的にゼロスケールなどの機能が導入されれば、コストの問題含め、多くのユースケースに対応できると個人的にも思いました。
Elasticのカルチャー
トピックではないですが、セッション中のディスカッションで、個人的に印象に残ったやり取りがあったので紹介します。
今や世界的な企業であるElastic社ですが、創業から組織が急拡大し、人数も増えていく中で文化をどう残し、維持していくかという質問がありました。
Elastic社には、https://www.elastic.co/about/our-source-code/ という明文化された文化があります。
こちらを遵守していくことはもちろんのこと、
- 家族との時間は大切にする
- 役職や上下関係なく率直に物事を伝える
- 怪我(異常)を放置しない
といった部分についても意識されているとのことです。
やり取りの中で、聞き逃してしまった部分もありますが、上記以外にもたくさんのことを意識されていることが垣間見れました。
まとめ
2日間にわたりブリーフィングに参加させていただき、非常に濃い経験をさせていただきました。
プロダクトの責任者から直接説明いただけたこと、また弊社以外にも各社様々な課題を抱えていたり、多角的な視点でディスカッションをしている場に居られたことは良い経験になったと思っています。
改めてこのような機会を提供いただいたElastic社に改めて感謝を申し上げたいと思います。
個人的には、足りていない知識領域の再確認や、モチベーション向上につながりました。
ML基盤チームとしては今後に活かせそうな施策があれば、積極的に取り入れて行きたいと思っています。
最後に、DMMではこのようなブリーフィングや海外カンファレンスなど、福利厚生の一環として参加できる制度があります。
気になる方はこちらからカジュアル面談も実施していますので、ぜひ応募お待ちしております。