

- はじめに
- パブリックプレビューのGemini 1.5 Proを早速試してみました
- Finopsセッション
- AIを活用できるか?
- 検索とAI
- Geminiに向けて強化されたインフラ
- Gemimi
- インフラ関連
- 気になったGemini関連と今後の利用など
- Gemini によるインフラ運用の進化
- Gemini Cloud Assist
- 今後の活用
- 最後に
はじめに
みなさん初めまして。動画配信開発部 配信インフラの佐藤と申します。
今回は社内でGoogle Cloudに携わっている各グループのリーダーの方々と共に、
2024年4月9日〜11日にかけてGoogle Cloud Next 24に参加してきました。
2015年から開催されているグローバルイベントでオンサイト時は都度サンフランシスコで開催されていましたが、昨今の治安の問題などもあり今年はラスベガスのMandalay Bay Convention Centerでの開催となっています。
本記事ではセッションの内容や新たな開催地の雰囲気なども含めお届けできればと思います。
パブリックプレビューのGemini 1.5 Proを早速試してみました
ITインフラ本部 SRE部の小野です。ようやくパブリックプレビューが公開されましたね。
Gemini 1.5 Proは最大100万トークンをサポートし、1時間のビデオ、11時間の音声などテキストデータはもとよりマルチメディアのデータの性能も大きく強化されました。
前バージョンと比較して画像理解能力が飛躍的に向上したモデルに対して、早速その能力を分析してみました。
分析対象は私がDMMブックスを担当していることもあり、漫画を正しく理解できているかという観点で分析しています。
なお、今回は作品権利の都合上、伏せていますので少し分かりにくいかもしれませんがご容赦ください。
今回漫画を分析するにあたってAIがどのように理解されているかを測るため、分析したものに対して以下の観点で質問することにしました。
- 文化的・社会的背景への理解
- 漫画の中にはしばしば文化や社会的背景を含んだ作品があります。それを理解することで物語に奥行きが出ます
- キャラクター理解
- 登場人物をきちんと見分けられているか確認してみます。当たり前ですがごっちゃになっていると面白みがわからないですよね
他にも実際に確認してみたのですが、今回はこの2つに焦点をあてて紹介しようと思います。
まず、Gemini 1.5 Proは特に申請しなくてもすでに利用可能になっています。
Vertex AIのマルチモーダルから「gemini-1.5-pro-preview-0409」モデルを選ぶことで利用できます。
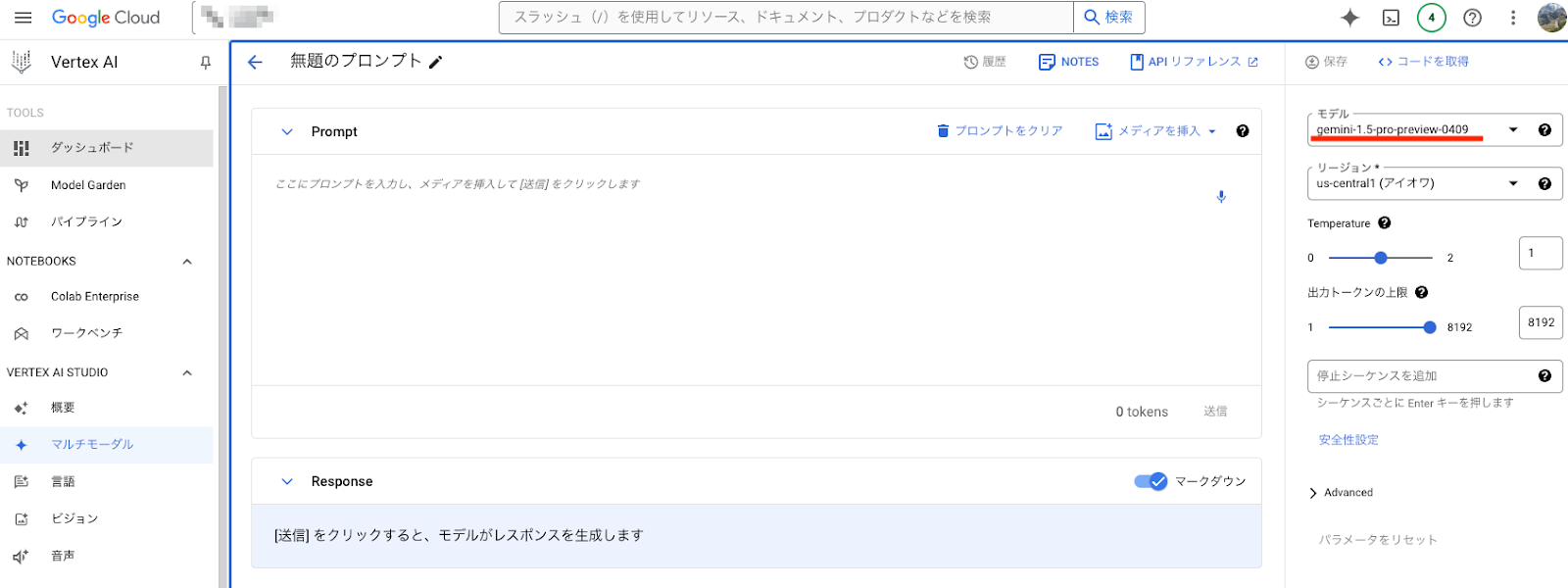
漫画を分析するにあたって、ファイル形式は画像、動画(画像を動画として結合)、PDFから選ぶことができます。
画像であれば3000枚、動画であれば音声なしで1時間、PDFは3000ページ50MB以下の制限があります。
また7MBを超える場合はGCSにアップロードして参照させる必要があります。
実は最初、複数の画像のアップロードが手間だと思ったのと、PDFが対応していることを知らなかったので、漫画を動画としてテストしていたのですが上手く分析できませんでした。
素直に画像またはPDFとして分析することをおすすめします。
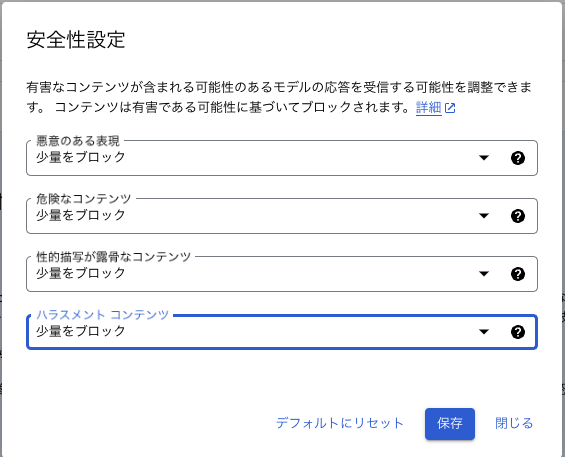
安全設定は極力ブロックしない設定にすることをおすすめします。今回の漫画作品は戦闘シーンがあることもあって、標準設定の「一部をブロック」では分析できないこともありましたのでなるべく安全設定は下げておいたほうが良さそうです。
実際にPDFを読み込ませてみると、200ページ程度の漫画では、概ね5万トークン程度で処理できるようです。
プロンプトあたりのページ数の上限は 300 ページのようなので、一般的なコミックは処理できますが、合冊版などページ数が多いものや、複数巻の分析は今は難しそうですね。
分析結果は対象の作品は日露戦争終結後の北海道が舞台であること、アイヌ民族を取り上げていることなど歴史的な背景をきちんと理解しており、登場人物の名前や説明なども正しくAIが漫画をきちんと理解できていることがわかりました。
ただ一方で登場人物の解説が、続巻で分かっていくことも書かれており、どうやらそのPDFだけで結果を出力しているわけではなさそうです。
この他にも描かれたキャラクターをどこまで識別しているか確認するため、何ページ目に誰が出ているか聞いてみましたが、主要キャラクターはきちんと判別できている一方でサブキャラーの判別が甘かったりとまだまだ改善の余地はあるようでした。
以上今回は簡単な分析に留まりましたが、Gemini 1.5 Pro は漫画の分析において一定の能力があることを示しましたが、まだまだ改善の余地があるかなと思います。
弊社サービスでは漫画大好きな編集部が漫画を紹介するサイトを運営しているのですが、まだまだその差はあるのかなと思います。一方でAIの進化は凄まじいのでこれからも定期的に確認をして、いつかAIが人以上のレベルになったときにはすぐに導入できるよう準備は進めて行こうと思います。
Finopsセッション
インフラ部の石井です。Google CloudのFinOps関連のセッションに参加しました。
弊社でもGoogle Cloudの利用は多く、クラウドコストを組織的に最適化するための
取り組みを継続的に行っています。
FinOpsは、以下の3つのフェーズを繰り返す活動となります。
「Inform(可視化)」→「Optimize(最適化)」→「Operate(実行)」
FinOpsのセッションでは、FinOps Scoreの全体平均は、「2.4/5」 と紹介されました。弊社は「3」 ということで、ある程度FinOpsに取り組めていると捉えられます。とはいえ各フェーズに対して、まだ探求すべき最適化の道が残されています。
(挑戦的なCUD適用「Optimize(最適化)」など)
「Inform(可視化)」のフェーズは、弊社ではCloud BillingのデータをBigQueryにエクスポートし、分析を行っています。より詳細なデータの確認が取れるようにアップデートされています。
「Optimize(最適化)」では、確約利用割引(CUD)を理解と管理し、最大限費用対効果を高めます。詳細化され、プロジェクト/リージョン/マシン対応別に詳細なレベルで分析できようになっています。
全体最適化ために、CUDを利用した効果を検証し対応したいと考えております。
「Operate(実行)」部分では、「cost anomaly detection for all」というアップデートがあり、AIが搭載され、過去の利用パターン分析から逸脱した要因の特定と分析が可能となりました。

- セットアップ不要で、30日以上の支出実績と6ヶ月の支出が $100を超えているアカウントで利用可能
プレビューとなるので、GCP契約形態により制限されますが、有効活用し、異常値の検出に取組みたいと考えております。
コスト最適化面でもAIを積極的に利用し、コストの最適化を実施していきたいですね。
AIを活用できるか?
プラットフォーム開発本部のpospomeです。
普段は本部全体の技術戦略の策定・推進を担当しています。
今回のCloud Nextは予想通り “AI推し” でした。しかし、初日のKeynoteを見たときに “AIに対する可能性” を感じました。以前から GitHub Copilot や Chat GPT などのAIプロダクトの存在は認識していましたが、私自身がAIに疎いこともあり、プログラミングだけでなくGoogle Cloud上での作業に至るまで一貫してAIがサポートしてくれる世界というのは衝撃的でした。なんとなく「アイアンマンのJ.A.R.V.I.S.みたいだな」と思いました。
Keynoteを見たあとは事前に予約していたセッションを見直して、AI関連のセッションへの参加に切り替えました。Google Cloud上でのAIサポートや開発ツールにAIを組み込む際の難しさなど、幅広い情報を体系的に得ることができました。
一方で “AI活用の課題” も感じました。それは “AIは嘘をつく可能性がある” という点です。実際にハンズオンに参加してGoogle CloudのGeminiを利用してみたのですが、質問によっては回答が間違っていました。私はある程度Google Cloudに対する知識があるので、間違いに気づき、改めて質問をし直したり、自身の知識でハンズオンを進めることができましたが、現在のAIの精度では、正誤判断できる程度の基礎力がなければ活用が難しいと感じました。ただ、基礎力があるエンジニアはAIに頼らなくても問題が解決できる可能性が高いので、そもそもAIを活用する機会が少ないのでは? とも思いました。
私はアーキテクトとして働いていることもあり、”自身がどのようにAIを活用するか” だけでなく、”組織として上手くAIを活用するにはどうすればいいか” を考える必要があるのですが、この課題に対してどうアプローチするか悩ましいところです。
今回たまたま Cloud Next に参加することができたのですが、結果的に自身のAIに対する認識を大きく変えるきっかけになりました。特に “プラットフォーム開発本部の各種システムにどのようにAIを組み込むのか” という課題に対する明確なイメージを持つことができたのは大きな収穫でした。
帰国後は早速AIに投資すべくチームのロードマップやメンバーへのタスクアサインを変更 しました。今後は何かしらの結果が出せるように頑張りたいと思います。
検索とAI
データサイエンスグループの西潟から,検索周りについて情報収集してきたのでお伝えします。
今回初めて Google Cloud Next に参加しましたが,思った以上に検索が全面に押し出されており,ニッチなタスクを預かっていると思っていた身としては,良い意味で将来に対する明るい展望と,日常との良い温度差を感じられました。
まず初めにカンファレンス参加の背景からお伝えします。
データサイエンスグループでは,DMM の全てのコンテンツをパーソナライズすることを目標に,検索・レコメンドプロダクトの開発/評価を行っています。
これまでのデータサイエンスグループでは,自然言語処理,機械学習,情報検索,画像解析などの要素技術を用いて検索・レコメンドの改善を行ってきました。
特に検索・レコメンドの relevancy 全般の改善をし始めてからは 3 年ほどが経過し,評価方法を含め,他社に引けを取らないレベルにまで改善タスクを進めてこられたと思っています。
検索ではプリプロセスとしてクエリリライト,ポストプロセスではベクトルリランキングやファセット書き換え,購買済みコンテンツ除去などでパーソナライズを実現し,これらの技術の応用として検索キーワードの自動生成など検索導線の追加タスクも実施してきました。
レコメンドでは深層学習やコンテンツベースのモデルにアップデートしてきたことや,ドメイン独自のペインポイントを解消するためのポストプロセスを追加することでレコメンド精度の大幅な向上を果たしてきました。
検索・レコメンドはその性質上,検索はユーザーの直接的なインタラクションを必要とする pull 型なプロダクトである一方で,レコメンドはインタラクションを必要としない push 型に分類されると考えられます。
これまでは便宜上これらのプロダクトを push 型,pull 型の違いで敢えて異なるプロダクトとして分類してきましたが,今回のカンファレンス参加で今後はますますプロダクトの境界が曖昧になり,少なくともデータソースや利用される機械学習モデルは融合していく世界観になると実感しました。
一方でこの世界観については特に現地に行かずとも,既に十分に感じられていたものではありますが,多くの人が同じように感じていそうという雰囲気を改めて実感できたというのは,やはりリアルなイベントの醍醐味だと思いました。
エコーチェンバーであると言われればそれまでですが,プロダクトの方向性を決めていく立場としては,得てして背中を押してくれる雰囲気は重要だったりします。
私が今回のカンファレンスで特に期待していたのは検索周りのプロダクトでした。
データサイエンスグループでは今後,動画,画像コンテンツからの自動タグ付けや,高度にパーソナライズされた検索に取り組み,ユーザーからのインプットを主体とする検索の脱却に挑戦していきたいと考えています。
レコメンドではユーザーが購買するコンテンツを直接提示するのに対し,検索ではユーザーからのインタラクションがないと始まらず,インタラクションの起点もフリーワード検索,もしくはジャンルなどの文字列情報をベースとしたリンクとなっています。
DMM で扱っている動画や電子書籍といったコンテンツは映像や画像であり,検索においては,これらのピクセル情報をベースとしたコンテンツに対して検索文字列で写像するというよく考えれば奇妙なタスクを行っていると言えます。
そのため,ユーザーは自身の検索意図を正確に把握し,それを文字列で表現する必要があり,コンテンツもその文字列をデータとして保持している必要あります。このインターセクションが正しく行われない限り,如何に多様なコンテンツを抱えていようとも,ユーザーは購買まで至ることができません。
本カンファレンスで終始主張されていた,データ統合や,それらを活用した RAG,動画や画像からの文字列情報の抽出については,改めてこれらの課題を解決する糸口になると感じられました。
我々の検索システムでは,まず足元の施策として,コンテンツの情報量を過不足なく保持することが必要だと考えられます。メタデータの整備はそのために必要不可欠であり,動画や画像からの自動タグ付けやそのデータを検索エンジンにシームレスに連携できる機能があるならとても有用です。
「Simplify the creation of generative apps with Vertex AI search as your RAG system」というセッションを始め,様々なセッションで vertex-ai-search と BigQuery や GCS とのシームレスな連携が紹介されていました。
DMM の検索エンジンはレガシーなブーリアン検索をベースなため,即 vertex-ai-search のようなベクトル検索をベースとした検索エンジンに移行することはラディカルすぎるため,現状では難しいと考えていますが,ソースレイヤーやスピードレイヤーと検索エンジンが非常に近いアーキテクチャを組めることは非常に有用だと感じました。現状の検索システムとの統合を考えても,スピードレイヤーでのデータ登録時に生成AIによるメタデータを拡張しつつインデクシングするようなことは容易に想像可能なため,データ統合の世界観はとても魅力的に感じています。
本セッションやその他のセッションにて一般的な LLM 活用を補足するために,追加情報を与えて検索精度を高める RAG やそのための langchain についてもよく見かけました。
DMM の検索ではできるだけユーザーにインプットやインタラクションをさせたくないので,対話による検索の可能性は低いと思ってはいますが,GCP では RAG の PoC は驚くほど簡単にできるため,まだ利用したことのない方は是非一度試してみることをオススメします。
こちらも本カンファレンスで初公開された情報ではないですが,私は今まで触ったことがなく,本カンファレンスでデモがされていたので触ってみたらあっけなく実行できました。以下は RAG の使用前後の結果です。RAG 使用後は DMMTV の情報を事前に与えているため,正しい情報が返せていることが分かります。
ここまでの結果を得るまでにかかる時間は大体5分程度です。途中手順が分からなくなったとしても,画面上に見える Gemini をボタンをクリックすれば対話的にサービスの利用をサポートしてくれます。
【使用前】
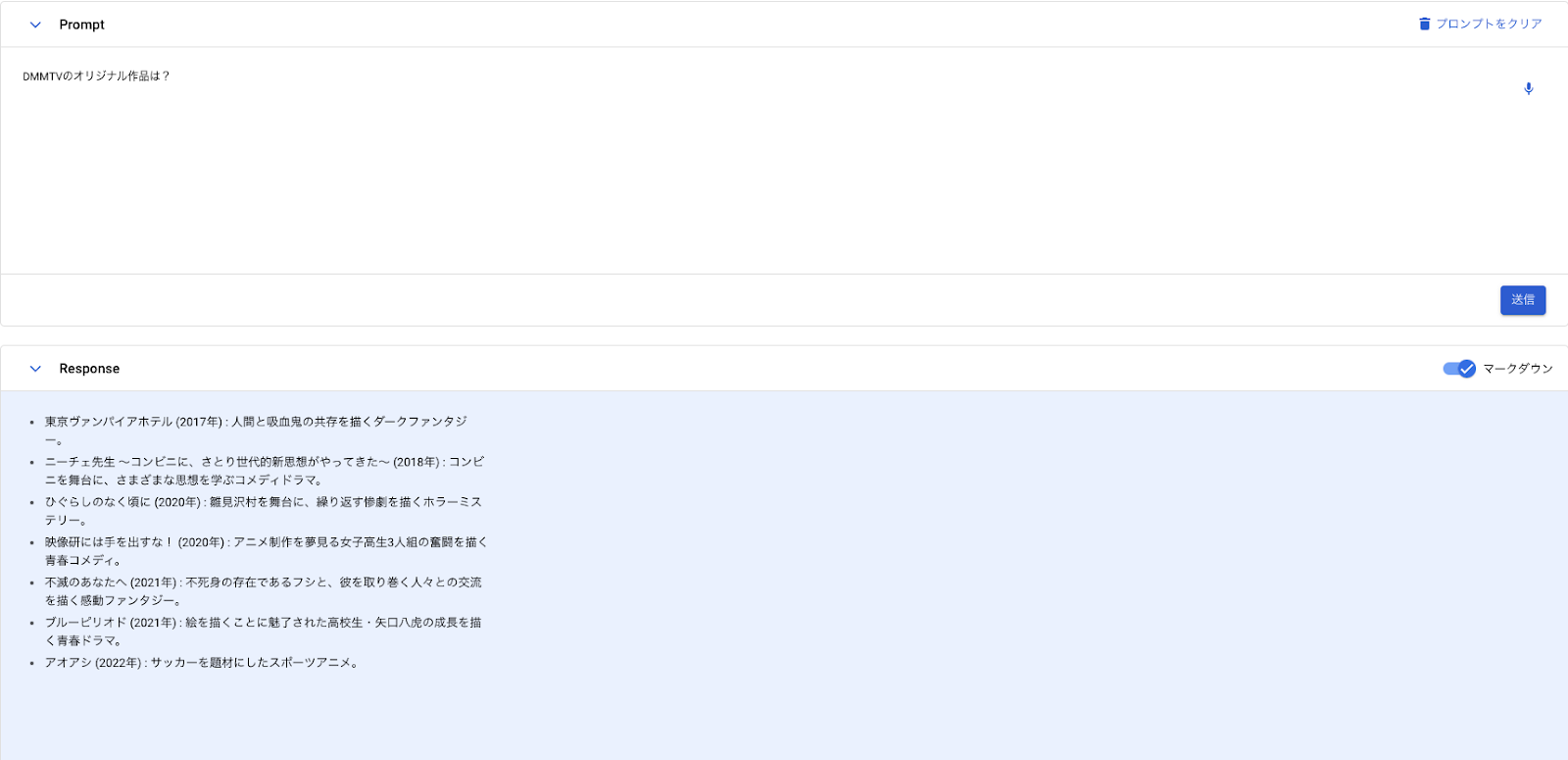
【使用後】
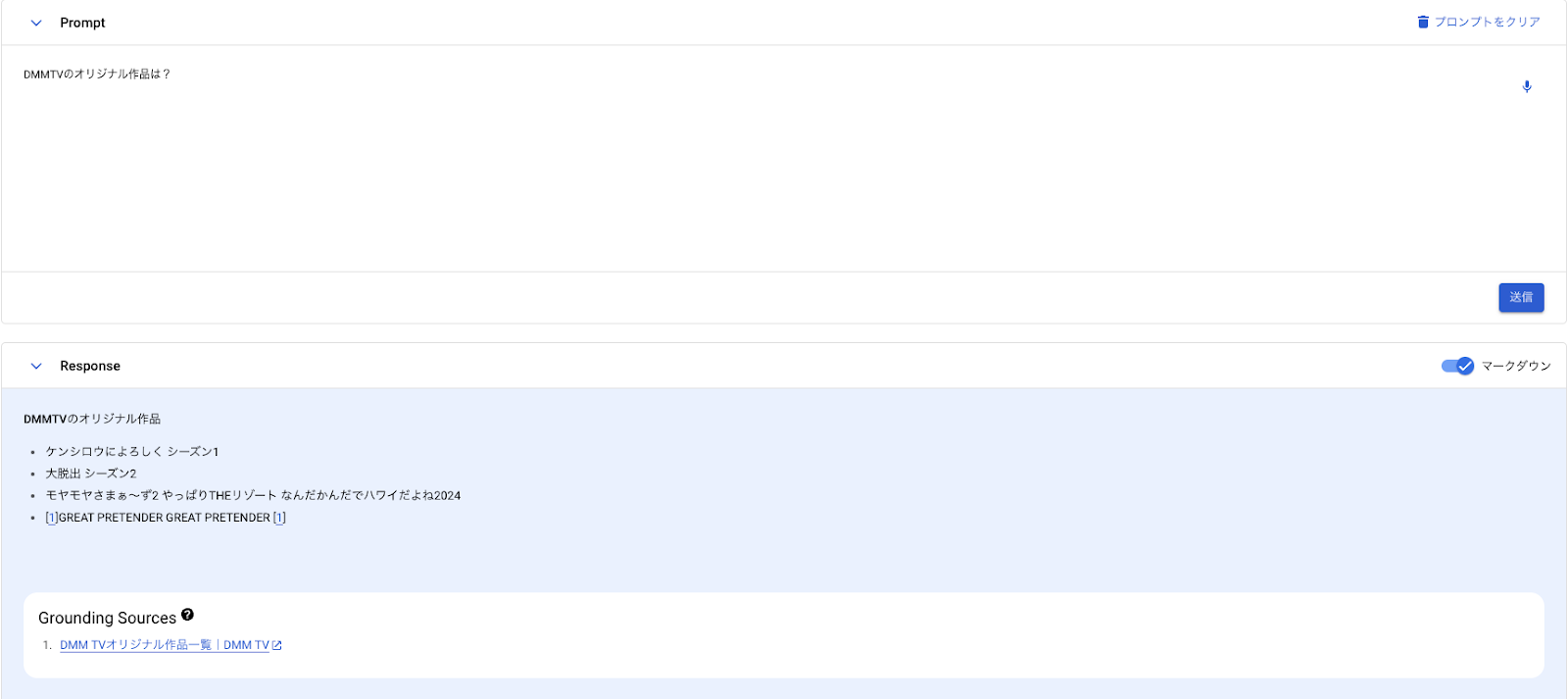
改めて検索やレコメンドに活用できそうなサービスや今後の方針がよく見えたカンファレンスであった印象でした。これまで日の目を見ることが少なかった検索システムがここまで大きく取り扱われているカンファレンスに参加できると,自信を持って今後のプロダクト開発に取り組めそうです。
一方で大体は日本国内にいても情報収集できる内容であったりするため,PdM と会話するなど現地にいかないとできないことを積極的にできる方が参加するべきだとも感じたカンファレンスでした。
Geminiに向けて強化されたインフラ
動画配信開発部の佐藤です。動画配信周りのインフラを担当しています。
今年は23年の同イベント時以上に生成AI周りがプッシュされており、過去リリースされた生成AI関連はGeminiに統合、リブランディングが図られていました。
どのセッションに参加してもGemini in 〜、with Geminiという形でAIに絡めたアップデートが伝えられており、
予習をしていなかった自分は理解できないところも多かったです。今回振り返るにあたって、AI周りを自分なりに整理してみました。
Gemimi
- googleの生成AIの総称
- テキスト・画像・動画・音声など複数のデータタイプを理解し、操作できるネイティブマルチモーダル対応のAIモデル
- 2023/12にリリースの対話型AIのbardはGeminiにリブランディング
- 今回のイベントでは Gemini for Google Cloud や Gemini for Google Workspaceとして、各サービスへGeminiを利用したAIによる運用支援機能が追加された
- Gemini Code Assist、Gemini Cloud Assist、Gemini in Security、Gemini in BigQueryなどが実際の支援機能
- 基本となるGeminiモデルは 1.5 pro がパブリックプレビューされ、Vertex AIなどのAI開発環境からもAPIとして呼べる形に
と、chatGPTやcopilotに少し出遅れたところを猛追し、生成AIおよび周辺のエコシステムの強化に全力で取り組んでいる、といった印象でした。

インフラ関連
上記の取り組み強化に合わせて、インフラ部分においてもより最適化が進められていました。
機械学習に特化したアーキテクチャである AI Hypercomputerが発表され、帯域幅を増強した NVIDIA H100 GPU 搭載A3 マシンのA3 Mega VM や、昨年末に発表され、v4から2.8倍高速となったTPU v5pなど、演算能力強化を中心としたアップデートが報告されました。それぞれGeminiのトレーニングで利用されるだけでなく、一般提供も今回アナウンスされ、より企業の独自AIモデルの利用促進や業務効率化を後押ししてくれている印象でした。

またAI関連とは別ですが、Google Axion Processors の発表は気になりました。
今までもArm の提供はありましたが、今回Google初の独自ArmベースCPUの発表が行われました。既存のArmより30%の性能向上、同世代のx86ベースインスタンスよりも性能が50%、エネルギー効率が60%向上しているとのこと。こちらも年内一般提供予定とのことです。
気になったGemini関連と今後の利用など
業務を楽にしてくれるな、と感じたのはGemini in Looker、Gemini in BigQueryの二つになります。自然言語で問い合わせを行うだけで分析、可視化、自動グラフ生成などがサポートされ、データさえあればクエリを書かずとも分析ができるようにサポートされ、状況判断に至るまでの情報整理のハードルがかなり下がったと感じました。
また、gcsのセッションではプレビュー版としてInsights Datasetsの作成と、実験版としてGeminiによるInsights分析のデモが行われ、自然言語を使用して簡単にストレージのフットプリント分析や費用の最適化などが簡単に行えることを確認しました。動画コンテンツのストレージを保守する立場としては今後の一般公開が楽しみに感じました。
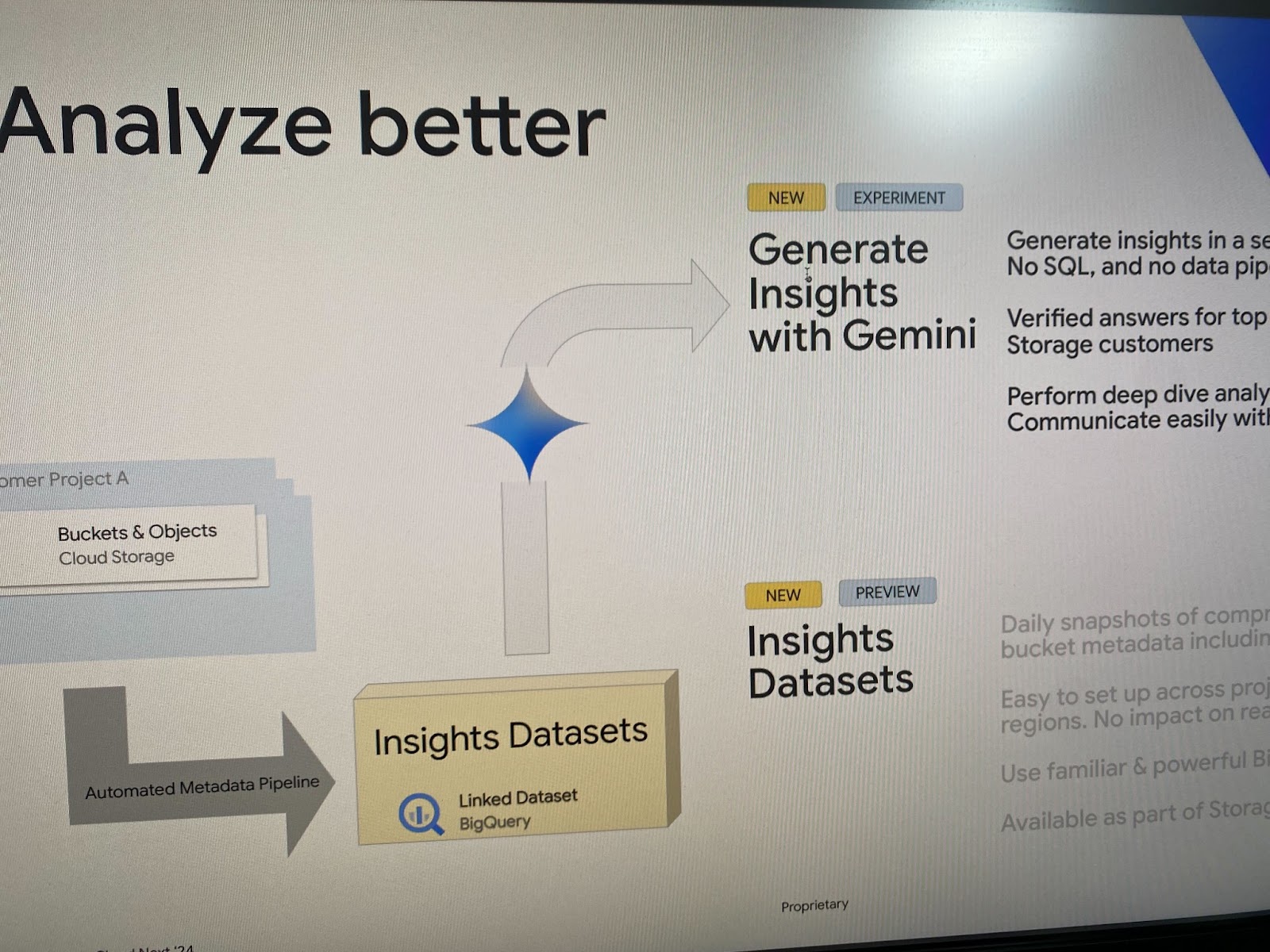
今回のイベント参加を通して、Googleの生成AIへの取り組みの本気度を認識できたことが一番大きな収穫だったと感じます。このようにGeminiを利用して運用保守を効率化することが当たり前の状況に変わっていく中で、立場上情報のインプットと業務への活用をしっかりとチャレンジしないといけないと強く感じました。
Gemini によるインフラ運用の進化
こんにちは。動画配信開発部配信インフラグループ動画SREチームでチームリーダーをやっている菅野です。
私は、2017年に新卒で入社をし、現在は動画サービスにおけるクラウド環境の開発・運用に携わっております。
その中でも DMM TV では Google Cloud を採用しており、主に Google Kubernetes Engine(GKE)や Cloud Spanner を利用しています。
DMM史に残る!「DMM TV」&「DMMプレミアム」開発秘話〜SREとバックエンドエンジニア編〜
そんな弊チームですが、現在私を含めて4名の体制で運用しており、サービスの規模の拡大や動画を支えるシステムが増える中で効率の良い運用が求められています。
そんな中で今回 Gemini Cloud Assist という運用や設計、最適化にAIを活用する仕組みが発表されました。
今回は、現地で実際に聞いてみた Gemini Cloud Assist の情報についてご紹介させていただきます。
Gemini Cloud Assist

2日目にあった Google Cloud Next '24 Developer Keynote にて Gemini Cloud Assit について紹介がありました。
ここでは実際のデモにてアラートの抽出やログのサマリだけでなく、どういった原因で障害になっているのか、直近の変更について、果ては解決のためのコマンドまでを Gemini に尋ねて解決策を導き出しています。
また、その解決のためのコマンドを Gemini のコンソールから直接 Cloud Shell を立ち上げて実行しています。
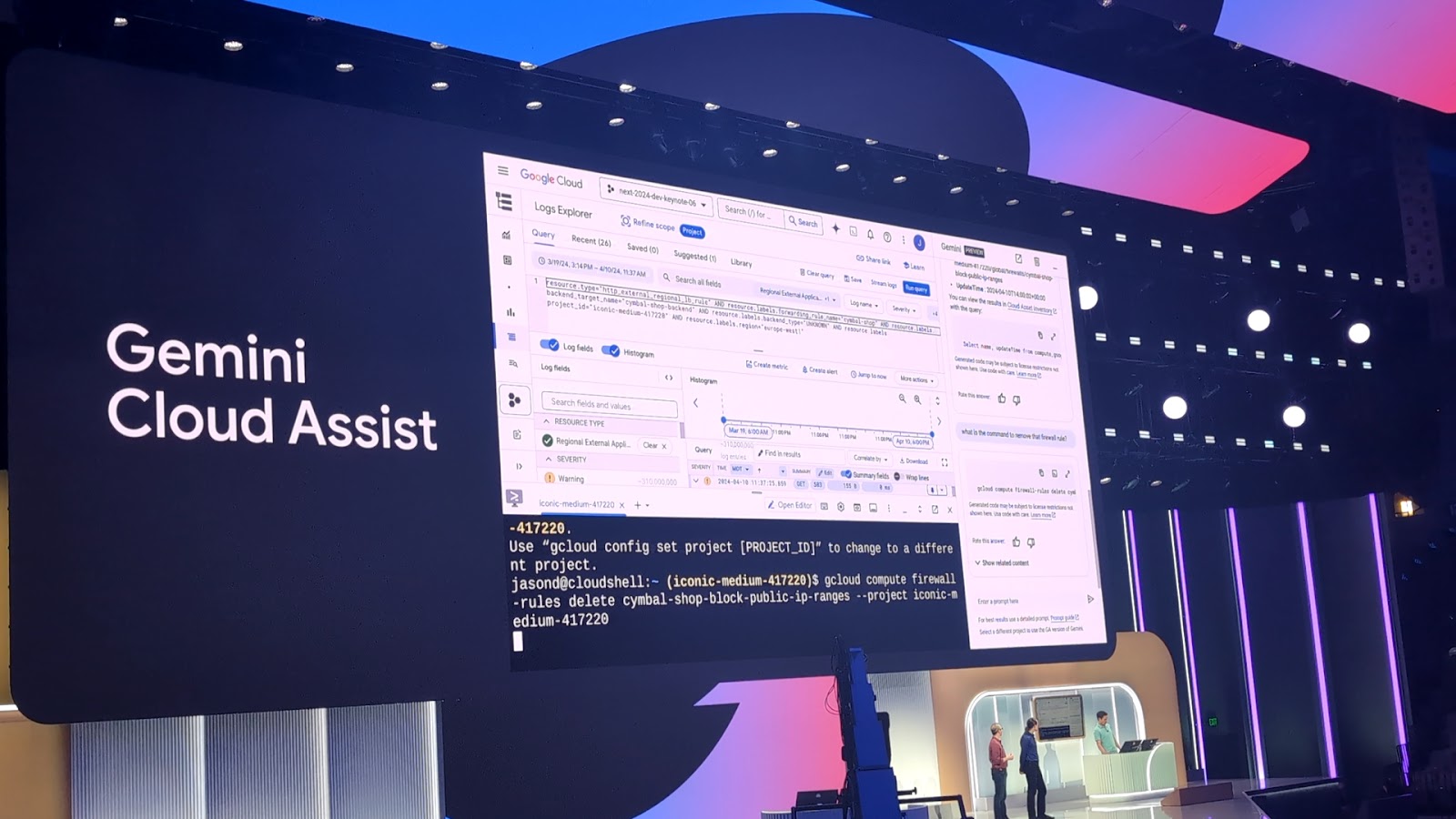
これはAIとクラウドプラットフォームが繋がったからこそ実現できることであり、この機能が GA されることにより様々な障害対応がより迅速に可能になると感じました。
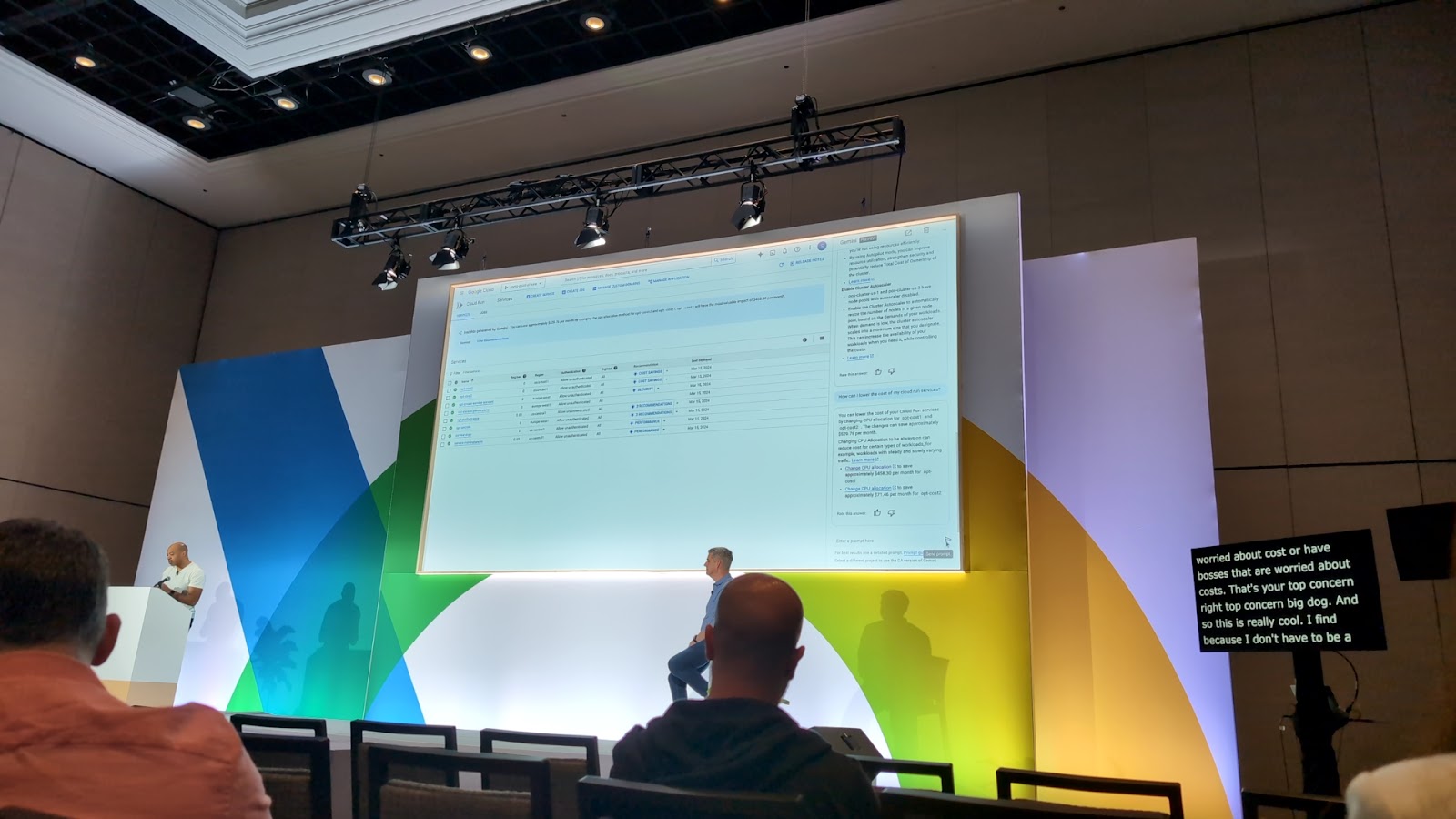
他にも Transform your cloud operations and design capability with Gemini Cloud Assist のセッションでは、 Keynote とは違った Gemini Cloud Assist の使い方について紹介していました。
一つは、インフラ構築をするにあたって最適な構成について質問しながらインスタンスを立てていくというものでした。
この機能を活用することで、やりたいことから必要なサイズのインスタンスについてGeminiに任せながら構築することができ、開発者はよりスピード感を持って環境構築が可能になります。

もう一つは、コストや運用における最適化について Gemini に尋ねることで今やるべきことを返してくれるということでした。
元々 Google Cloud では Active Assist という最適化における推奨事項を教えてくれる機能がありますが、Gemini と組み合わせることでより自分たちに最適な選択肢を選ぶことができるようになると感じました。
今後の活用
今回発表のあった Gemini Cloud Assist についてはまだ Private Preview という状態ですが、活用することで開発者のインフラ構成の理解や障害の調査に役立ち、開発者はより開発に集中でき、インフラを担当する人はより最適なアーキテクチャ設計に注力ができるようになると強く感じました。
特に、一番活用できる箇所としては新しいメンバーの参入時の構成理解における障壁を崩すのに大きく役に立つと考えており、利用できるようになったタイミングでは積極的に取り入れていく予定です。
冒頭にもお話しましたが、現在、我々動画SREチームでは私含めて4人の体制で運用を行っています。
Gemini Cloud Assist を使った効率的な運用も目指していきたいところですが、採用についても積極的に行っております。
興味を持たれた方はぜひご応募ください。
最後に
Google Cloud Next での発表は、生成AIのセッションが7割ほど占めており、
EXPOでの企業展示も多くが、生成AIを絡めた企業が多く展示されておりました。
また、多くの日本企業、パートナー会社の方も参加されており、現地でのつながりを
持つことができました。
弊社でもAIを積極的に採用しております。
ご興味頂ける方は、各セクションで、一緒に働く仲間を募集しております。