

1. はじめに
日々、開発業務に携わる皆さま、お疲れ様です。プラットフォーム戦略室EMのさるのすけです。私たち開発者は、日々「効率よくもっと作業を進めたい」「チーム全体の成果を最大化したい」と願っているのではないでしょうか。このように、開発の現場では、より良い開発プロセスを探求しています。
エンジニアの生産性可視化の重要性
ソフトウェア開発において、エンジニアの生産性を可視化することは、プロジェクトの成功やチームの効率性向上に直結します。
生産性を適切に把握することで、以下4つのメリットが得られると考えています。
- 課題の早期発見: 生産性低下の兆しを早期に発見し、迅速に対応することで、潜在的な問題の深刻化を防ぐことができます。
- フィードバックサイクルの改善: 生産性データを基にしたフィードバックにより、エンジニアのスキル向上やモチベーションの維持・向上が期待できます。
- 意思決定の精度向上: 生産性に関する客観的なデータを持つことで、プロジェクト管理や戦略的な意思決定がより精度高く行えるようになります。
- リソースの最適化: 生産性の高いエンジニアやチームにリソースを集中し、プロジェクトの進行を加速させることが可能になります。
本記事の目的と概要
本記事では、エンジニアの生産性を可視化するための具体的な方法について解説します。指標の選定から可視化ツールの選定、運用プロセスまで、実践的な内容を網羅的に扱います。
2. 指標の選定
生産性を測定するための指標
エンジニアの生産性を測る指標として、代表的なものに「Four Keys」と「SPACE」があり、指数を決める際に参考にしたため下記にて説明させていただきます。
Four Keysは、DevOpsの実践において重要な4つの指標で構成され、高パフォーマンスなチームの特徴を示します。
- デプロイメント頻度: コードが本番環境にリリースされる頻度です。この頻度が高いほど、フィードバックループが短くなり、迅速な改善が可能になります。
- 変更リードタイム: コード変更が完了するまでの時間です。この時間が短いほど、新しい機能や修正を迅速に提供できます。
- 変更失敗率: デプロイ後に問題が発生する割合です。この割合が低いほど、デプロイの品質が高いことを示します。
- 復旧時間: 問題発生から復旧までの時間です。この時間が短いほど、システムの信頼性が高いと言えるでしょう。
SPACEは、エンジニアの満足度やパフォーマンスなど、より広範な側面から生産性を評価するモデルになります。
- 満足度と幸福感: エンジニアの仕事に対する満足度や幸福感を測ります。
- パフォーマンス: コードの品質や実装効率など、エンジニアの成果を測ります。
- 活動量: コミット数やプルリクエスト数など、エンジニアの活動量を数値化します。
- コミュニケーションとコラボレーション: チーム内のコミュニケーションの円滑さを測ります。
- 効率とフロー: エンジニアの作業効率やスムーズさを測ります。
自部署に適した指標の選定方法
自部署では、Four Keysの「変更リードタイム」という概念を参考に、開発プロセスの各フェーズにおけるリードタイムを詳細に計測することで、ボトルネックを特定し、開発効率の向上を目指しました。また、SPACEの「パフォーマンス」を測る指標として、エンジニアの貢献度や開発活動の活発さを定量化することで、チーム全体の生産性を評価できるようにしました。
具体的には、GitHubエンタープライズや「従業員の勤怠&工数管理サービス『TeamSprit』」から取得したデータを用いて、以下の主要指標を選定しました。
- プルリクエストからマージまでの平均時間: 各プルリクエストの全体的な処理時間を把握し、開発プロセス全体の効率を評価します。
- プルリクエストからレビュー開始までの平均時間: レビュー開始までの時間を短縮することで、早い段階でフィードバックを得て、品質向上につなげます。
- レビューからアプルーブまでの平均時間: レビュー過程の効率を評価し、レビューの質向上を目指します。
- アプルーブからマージまでの平均時間: マージまでの時間を短縮することで、開発サイクルを加速させます。
- プルリクエスト数: 開発活動の慎重さを測り、チーム全体の生産性を評価することが期待できます。
- アクティブ人数: チーム全体の活性を示す指標であり、プロジェクトへのエンゲージメントの高さを表します。
- 平均変更行数: コード変更の規模を把握し、大規模な変更によるリスクを評価することができます。
- エンジニアの貢献度: 各エンジニアの貢献度を定量化することで、適切な評価や育成に繋げることができます。
これらの指標を通じて、開発プロセスのボトルネックを特定し、チーム全体の生産性を向上させることで、最終的にはプロダクトのリリースサイクルを短縮し、顧客への価値提供を加速させることを目指します。
指標選定の際の注意点
指標を選定する際には以下の4点に注意しました。
- 偏りの防止: 特定の指標だけに頼ってしまうと、生産性全体の評価が偏りがちです。そのため、様々な面から生産性を測定できるように、多様な指標を設定しました。
- 組織の目標と整合性: 指標は、組織の目標と一致している必要があります。例えば、効率的なコードレビュープロセスが重要であれば、マージまでの時間が重要な指標となります。
- データの信頼性: データが正確であることが前提です。不正確なデータに基づいた指標は、誤った結論につながる可能性があります。
- チームのインプット: 指標選定の際には、チームからのフィードバックを積極的に取り入れ、現場の状況に合った指標となるよう努めました。
3. 指標の可視化
データ収集の方法
エンジニアの生産性を見える化するためには、まず必要なデータを適切に収集することが不可欠で、自部署では、以下の方法でデータを収集しましたのでご参考にしてください。
- GitHubエンタープライズのAPI: プルリクエスト(PR)の詳細情報を取得するために、GitHubエンタープライズのAPIを使用しました。詳細情報は以下のURLから取得できます。
- PR詳細情報のURLサンプル: https://{domain}/repos/{owner}/{repo}/pulls/{pull_number}
- GitHub ActionsのAPI: デプロイ情報はGitHub ActionsのAPIを用いて収集しました。デプロイ関連のデータは以下のURLから取得しています。
- デプロイ情報のURLサンプル: https://{domain}/repos/{owner}/{repo}/actions/runs
- TeamSpiritからのエンジニア属性情報: エンジニアの属性情報については、TeamSpiritから取得しています。各エンジニアの役割やチームに関する詳細が含まれます。
- データ収集プログラム: データ収集プログラムはPythonで作成しました。以下にサンプルコードを示します。
import os from dotenv import load_dotenv import requests from datetime import datetime # .envファイルを読み込む load_dotenv() # 環境変数からAPIトークンを取得 API_TOKEN = os.getenv("GITHUB_API_TOKEN") def get_headers(token): return {"Authorization": f"token {token}"} def get_pr_details(repo_owner, repo_name, pr_number, token): url = f"https://{domain}/api/v3/repos/{repo_owner}/{repo_name}/pulls/{pr_number}" headers = get_headers(token) response = requests.get(url, headers=headers) return response.json() def get_deploy_info(owner, repo, token): url = f"https://{domain}/api/v3/repos/{owner}/{repo}/actions/runs" headers = get_headers(token) response = requests.get(url, headers=headers) return response.json() def get_pr_list(repo_owner, repo_name, token): url = f"https://{domain}/api/v3/repos/{repo_owner}/{repo_name}/pulls" headers = get_headers(token) response = requests.get(url, headers=headers) return response.json() def calculate_contributions(pr_list, engineer_username): contributions = {'total_prs': 0, 'open_prs': 0, 'closed_prs': 0, 'merged_prs': 0} for pr in pr_list: if pr['user']['login'] == engineer_username: contributions['total_prs'] += 1 if pr['state'] == 'open': contributions['open_prs'] += 1 elif pr['state'] == 'closed' and pr['merged_at'] is None: contributions['closed_prs'] += 1 elif pr['merged_at'] is not None: contributions['merged_prs'] += 1 return contributions def main(): repo_owner = "your_repo_owner" repo_name = "your_repo_name" engineer_username = "specific_engineer_username" # PRの詳細情報を取得 pr_number = 1 pr_details = get_pr_details(repo_owner, repo_name, pr_number, API_TOKEN) print(f"PR詳細情報: {pr_details}") # デプロイ情報を取得 deploy_info = get_deploy_info(repo_owner, repo_name, API_TOKEN) print(f"デプロイ情報: {deploy_info}") # PRリストを取得し、特定のエンジニアの貢献度を計測 pr_list = get_pr_list(repo_owner, repo_name, API_TOKEN) contributions = calculate_contributions(pr_list, engineer_username) print(f"エンジニア {engineer_username} の貢献度: {contributions}") if __name__ == "__main__": main()
コードの処理の流れ
環境設定
- envファイルからGitHubのAPIトークンを取得します。
- GitHub APIへのリクエストに必要なヘッダーを生成する関数get_headersを定義します。
GitHub APIへのリクエスト
- get_pr_details: 特定のPRの詳細情報を取得します。
- get_deploy_info: リポジトリのデプロイ情報を取得します。
- get_pr_list: リポジトリ内の全てのPRリストを取得します。
貢献度の計算
- calculate_contributions: 取得したPRリストから、指定したエンジニアが作成したPRの数を、状態別に(オープン、クローズ、マージ済み)集計します。
結果の出力
- 各API呼び出しの結果と、エンジニアの貢献度をサンプルではコンソールに出力します。
可視化ツールの選定
収集したデータをより効果的に活用するために、可視化ツールを選定しました。いくつかのツールを比較検討した結果、Lookerを採用することにしました。
比較検討したツール
| ツール名 | メリット(主な特徴) | デメリット(課題) |
|---|---|---|
| Grafana | 高度なダッシュボード作成機能、リアルタイムデータの可視化 | 初期設定が複雑/習得に時間がかかる |
| Power BI | ユーザーフレンドリーなインターフェース、多機能なビジュアライゼーション | コストが高い/データセットの更新が比較的遅い |
| Looker | 高度なデータモデリング機能、カスタマイズ性が高い、強力なビジュアライゼーション機能 | 通常設定に時間がかかる場合がある |
Lookerを選定した理由
Lookerは、導入実績が豊富で、ノウハウも蓄積されているため、スムーズな導入が見込めます。さらに、柔軟なデータモデリング機能により、開発特有の指標を定着させ、業務改善に貢献できると考え、採用に至りました。 以下のサンプルグラフを参考に、具体的な指標の説明をします。
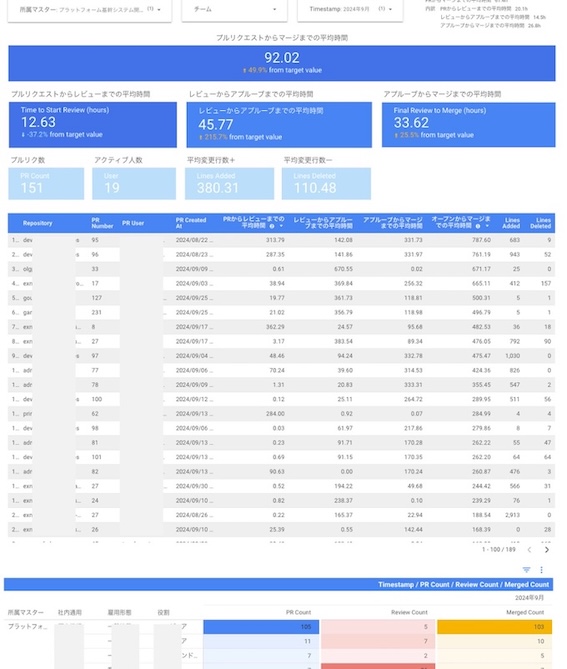
ダッシュボードの説明と評価ポイント
| 指標名 | 説明 | 評価ポイント |
|---|---|---|
| プルリクエストからマージまでの平均時間 | プルリクエストが作成されてからマージされるまでの平均時間を示し、開発プロセスの全体的な効率を評価します。 | 短い時間でマージできれば、開発サイクルを高速化し、迅速な機能追加が可能になります。ただし、品質が犠牲にならないよう注意が必要です。 |
| プルリクエストからレビューまでの平均時間 | プルリクエストが作成されてから最初のレビューが開始されるまでの平均時間を示し、レビュー開始の迅速さを評価します。 | 短い時間でレビューを開始できれば、問題の早期発見と解決に繋がり、品質向上に貢献します。 |
| レビューからアプルーブまでの平均時間 | レビューが開始されてから承認されるまでの平均時間を示し、レビューの効率を評価します。 | レビュー時間が短縮されると、開発のボトルネックとなることを防ぎ、開発速度の向上に繋がります。 |
| アプルーブからマージまでの平均時間 | 承認されたプルリクエストがマージされるまでの平均時間を示し、マージまでの迅速さを評価します。 | マージまでの時間が短縮されると、開発成果が迅速に反映され、ユーザーへの価値提供が早まります。 |
| プルリクエスト数 | 一定期間におけるプルリクエストの総数を示し、開発活動の活発さを評価します。 | プルリクエスト数が多いほど、開発が活発に行われていると考えられます。ただし、品質を犠牲にして数量を追求しないよう注意が必要です。 |
| アクティブ人数 | プロジェクトに積極的に関与しているエンジニアの人数を示し、リソースの効率性を評価します。 | 人数が多すぎるとコミュニケーションコストが増加し、少なすぎると開発速度が低下する可能性があります。 |
| 平均変更行数 | プルリクエストごとの平均変更行数を示し、開発規模や変更の頻度を評価します。 | 変更行数が大きすぎると、バグ混入のリスクが高まる可能性があります。逆に、小さすぎると、開発が細切れになり、非効率になる可能性があります。 |
| エンジニアの貢献度 | 各エンジニアのコミット数、レビュー件数、コードの品質などを総合的に評価し、個々の貢献度を可視化します。 | 各エンジニアの強みや弱みを把握し、適切なタスクの割り当てや育成に役立てます。 |
その他参考
| グラフ1 | グラフ2 |
|---|---|
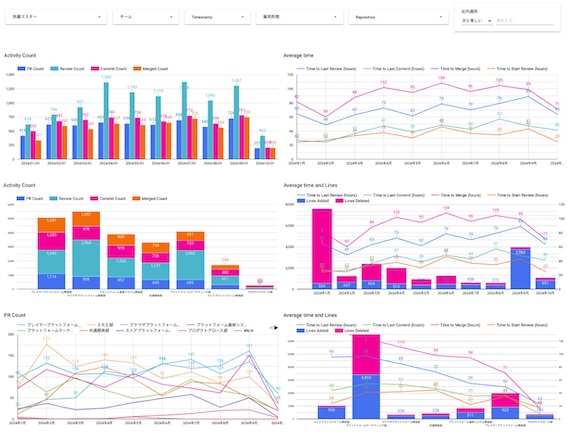 |
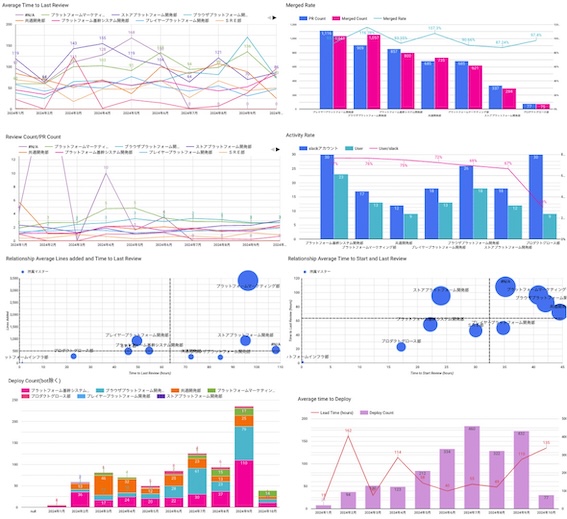 |
これらのグラフやダッシュボードを通じて、生産性の指標をビジュアル化し、チームのパフォーマンス改善に役立てています。
4. 運用プロセスの確立
運用開始時のトラブルシューティング
運用開始時には、予期せぬトラブルがつきものです。このようなトラブルに迅速に対応することで、システムの安定稼働を目指します。
- データ収集の不具合
- 対応方法: データ取得スクリプトが正常に動作しているか確認し、APIのレスポンスステータスをチェックします。エラーログを確認し、問題の詳細を特定します。
- 例: GitHub APIのレートリミットに達した場合、適切なウェイトを設けるか、APIトークンを増やして対応します。
- 対応方法: データ取得スクリプトが正常に動作しているか確認し、APIのレスポンスステータスをチェックします。エラーログを確認し、問題の詳細を特定します。
- データの不整合
- 対応方法: データベースの一貫性チェックを定期的に行い、不整合が見つかった場合には補正処理を実施します。必要に応じてデータクレンジングスクリプトを実行します。
- 例: PR作成日時とマージ日時に矛盾がある場合、手動でデータを確認・修正します。
- ダッシュボードの表示エラー
- 対応方法: ダッシュボードの設定やフィルタリング条件を再確認し、エラーの原因を特定します。必要に応じてLookerのサポートを活用します。
- 例: グラフが表示されない場合、データソースの接続設定やクエリの内容を確認します。
継続的なモニタリングとフィードバックの重要性
システムの運用が安定した後も、継続的なモニタリングとフィードバック収集を行うことで、常に最適な運用状態を維持することが重要になります。
- データモニタリング
- 定期的なチェック: データ収集プロセスやデータベースの健全性を定期的にチェックし、不具合が発生していないかを確認。
- アラート設定: 特定の条件下でアラートを設定し、異常が検知された場合には迅速に対応します。
- フィードバックの収集
- チームからのフィードバック: ダッシュボードの使用感や指標の有用性について、定期的にチームからフィードバックを収集。
- 改善策の実施: フィードバックを基に、指標の追加やダッシュボードの改良を継続的に行います。
- 報告と共有
- 定期レポート: 生産性指標の定期レポートを作成し、チーム全体や本部長へ共有。
- レビュー会議: 定期的にレビュー会議を開催し、生産性向上の進捗や新たな課題について議論を行います。
チーム全体での生産性向上に向けた取り組み
可視化されたデータを基に、チーム全体で生産性向上に向けた取り組みを行います。
- 目標設定
- 具体的な目標: 可視化データを基に、具体的かつ達成可能な目標を設定します(例:レビュー時間を1週間で20%短縮)。
- 進捗管理: 設定した目標に対する進捗を定期的にモニタリングし、目標達成度を評価します。
- 改善アクション
- プロセスの見直し: データに基づいて、コードレビューやデプロイメントプロセスの改善策を実施。
- トレーニングと教育: 生産性向上のために必要なスキルや知識をチーム全体で共有し、トレーニングセッションを開催します。
- エンゲージメントの向上
- チームの意識向上: データに基づいた成功事例を共有し、エンジニアのモチベーションを高める。
- フィードバックカルチャーの醸成: 継続的なフィードバックを通じて、オープンで協力的なチームカルチャーを育みます。
これらの取り組みを複合的に行うことで、チーム全体の生産性とパフォーマンスを持続的に向上させることが可能となります。
5. 結論
エンジニアの生産性可視化の効果
エンジニアの生産性を可視化することによって、我々のチームとプロジェクト運営には数々の具体的な効果と恩恵がもたらされていると感じています。
- リソースの適正配分:生産性指標を通じて、どのエンジニアやチームが高いパフォーマンスを発揮しているかを把握し、リソースを効果的に再配分することができるようになった。これにより、プロジェクトの進行速度の向上へ寄与した。
- 課題の早期発見と迅速な対応:各種指標を継続的にモニタリングすることで、生産性が低下している箇所を早期に発見し、迅速に対応策を講じることが可能となりました。例えば、レビュー時間が長引くケースに対しては、レビュー工程の見直しやトレーニングを実施しました。
- フィードバックループの改善:生産性データに基づくフィードバックをもとに、エンジニア一人ひとりがどの部分で改善すべきかを明確に把握できるようになりました。これにより、個々のスキルアップと全体のプロセス効率向上が実現します。
- 意思決定の精度向上:客観的なデータをもとにした意思決定が可能となり、プロジェクトのリスク管理やスケジュール管理が精度高く行えました。この結果、プロジェクトの成功率が向上しています。
今後の展望と課題
生産性可視化の取り組みは大きな成果を上げましたが、依然として課題や今後の展望が存在します。
- 1. データのさらなる拡充
- 現在のデータ収集と可視化をさらに充実させ、新しい指標やデータソースを取り入れることで、より包括的な生産性の把握を目指す必要があります。
- 2. リアルタイムモニタリングの強化
- データのリアルタイム性をさらに高めるため、リアルタイムモニタリングと自動アラート機能を強化し、迅速な対応を目指します。
- 3. チームのエンゲージメント向上
- 生産性データの活用方法について、エンジニアチーム全体の理解と納得を得るために、透明性の高いコミュニケーションと教育を継続して行います。
- 4. 継続的改善の文化の醸成
- 生産性可視化システムを単なるツールとしてではなく、継続的な改善を促進する文化の一環として定着させます。フィードバックカルチャーの強化とエンジニアの自主性を尊重する環境づくりを進めます。
これらの課題をクリアすることで、エンジニアの生産性向上とプロジェクトの成功率をさらに高めることができると信じています。本記事が皆さまの取り組みにお役立てれば幸いです。
国内最大級のゲームプラットフォーム「DMM GAMES」を運営するEXNOAでは、未来のゲーム体験を創る仲間を募集しています!